Вангуем Session ID с помощью Burp Sequencer
Всякий раз, когда мы входим в приложение, сервер выдает Session ID или token, которые являются уникальными. Но что, если бы мы могли угадать следующий уникальный идентификатор сеанса, который будет сгенерирован сервером?
Сегодня попробуем обогнать алгоритм приложения и войти в него, выдавая пользователя с прогнозируемым Session ID.
Содержание:
-
Введение в Burp Sequencer
-
Эксплуатация Session ID в Sequencer
-
Ручной анализ запросов
-
Сравнение захваченных токенов
Введение в Burp Sequencer
Burp Sequencer – это инструмент для анализа качества случайности в выборке элементов данных.
Элементами данных могут быть:
-
идентификаторы сеанса приложения
-
токены CSRF
-
токены сброса или забытого пароля
-
любой конкретный непредсказуемый идентификатор, созданный приложением
Burp Sequencer – один из самых удивительных инструментов, который пытается зафиксировать случайность или дисперсию идентификаторов сеанса с помощью некоторых стандартных статистических тестов, которые основаны на принципе проверки гипотезы на выборке доказательств и расчета вероятности появления наблюдаемых данных.
Инструмент тестирует образцы в нескольких различных сценариях, будь то анализ на уровне символов или на битовом уровне. Проанализированный результат будет выдан в формате с наилучшей сегрегацией. Более подробно про принцип работы Burp Sequencer изложено в его документации.
Главное достоинство секвенсора в том, что он доступен для обеих версий Burp. После установки приложения вкладка Sequencer будет на верхней панели.

Эксплуатация Session ID в Sequencer
Будь то базовый идентификатор сеанса или токен, сгенерированный на стороне сервера, sequencer проанализирует все, ведь единственным требованием является запрос, которым он передается.
Давайте запустим анализатор в секвенсоре, захватив и поделившись идентификатором сеанса входа из нашего любимого уязвимого приложения bWAPP, которое идет в комплекте с Kali Linux и другими ОС для белого хакинга.
Введите целевой IP-адрес в браузере и войдите в систему с помощью bee: bug.
Подождите! Мы правильно говорили об идентификаторе сеанса входа в систему, поэтому включим прокси-службу, а затем нажмем кнопку «Login».
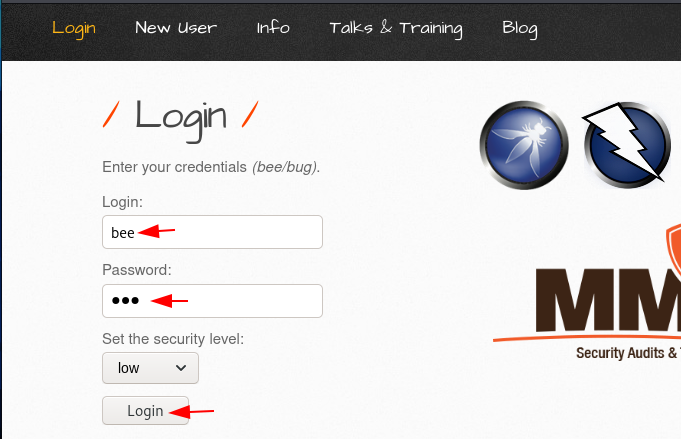
Проверяем захватил ли burp запрос или нет. Из захваченного запроса мы видим, что PHPSESSID находится в заголовке Cookie, давайте поделимся полным запросом с Sequencer, щелкнув правой кнопкой мыши по пустому пространству.
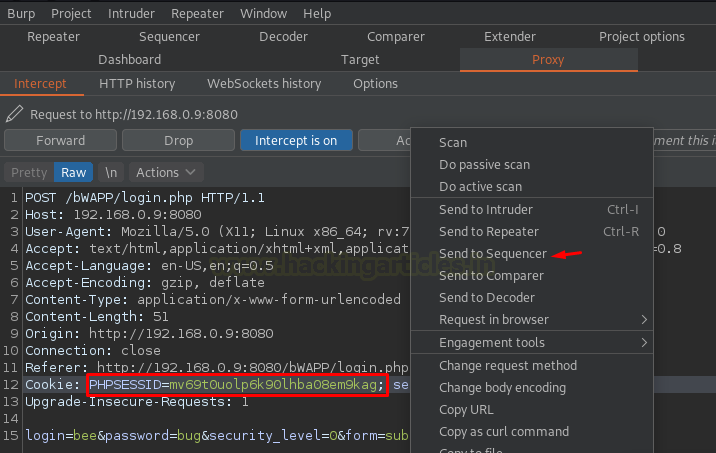
Как только Sequencer получает запрос, пустые поля заполняются непосредственно идентификатором Token ID, который идет с «Response» для конкретного общего запроса.

Однако бывают случаи, когда мы хотим проанализировать другое значение. В таких ситуациях burp suite дает возможность определить Custom location. Давай проверим это.
Нажмите кнопку «Custom location» ниже для параметра cookie и затем откройте настройки. Как только мы это сделаем у нас появится новое окно с названием «Define Custom token location», в котором мы получаем ответ на наш общий запрос.

Кроме того, мы можем выбрать определенные параметры:
-
Define start & end
-
Extract from regex group
Давайте проверим первый.
Когда мы наводим курсор и выбираем значение из общего ответа, мы получаем некоторые манипуляции с ограничителями начала и конца. Нажимаем кнопку «Save» и наше custom location будет определено на панели.

Теперь просто нажмите кнопку «Start Live Capture», выбрав параметр «Cookie» в разделе «Token Location within Response».
Когда мы это сделаем появится новое коно [ Live capture #1 ].
Как только загорелась кнопка «Start Live Capture», Burp повторил исходный запрос (примерно около тысячи раз) и таким образом извлек все токены, полученные из ответов.
Однако, как только страница захвата загружается, отображается индикатор выполнения со счетчиком сгенерированных токенов и запросов, сделанных секвенсором.
Кнопки окна Live Capture:
-
Pause/Resume – ставит процесс на паузу, чтобы помочь пентестеру проанализировать запросы, сгенерированные до этого момента.
-
Copy Tokens – помогает скопировать все сгенерированные рандомизированные токены.
-
Stop – полная остановка процесса.
-
Save Tokens – сохранение случайно сгенерированных токенов в определенный файл.
-
Auto analyze – сбрасывает проанализированные результаты, после генерирования определенного количества токенов.
-
Analyze now – при нажатии выводит на экран отчет. Работает только в том случае, если количество сгенерированных токенов более 100.
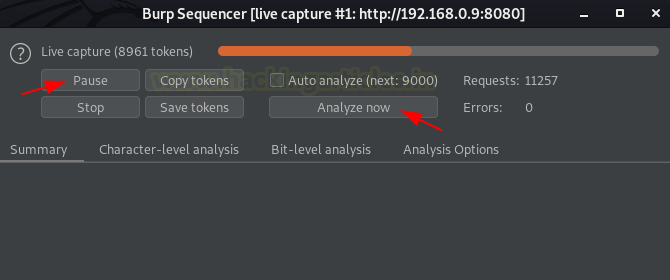
Итак, давайте поставим на паузу секвенсор, а затем нажмем кнопку «Analyze now», чтобы узнать, что он собирает.
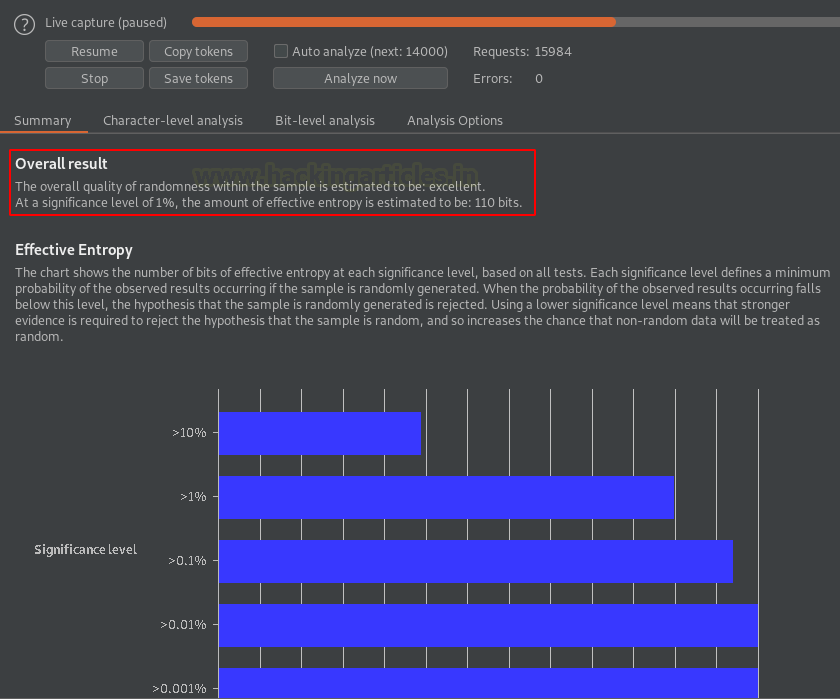
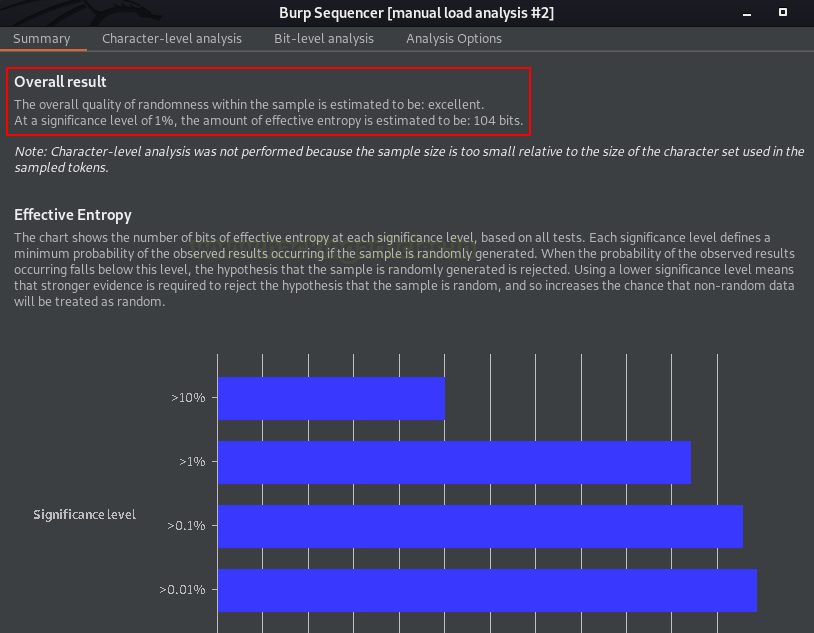
Из изображения ниже мы видим, что секвенсор проанализировав около 16000 запросов, а общее качество случайности в выборке получило оценку «отлично».
Мы могли бы получить качество случайности как «плохое», если бы идентификатор сеанса веб-приложения повторялся.
Однако эффективная энтропия составляет 110 бит, что считается хорошим значением, поскольку:
-
наименьшее значение – 64
-
наилучшее значение – 128
Burp Sequencer работает поверх Sample, поэтому при большом количестве захваченных токенов будет получен лучший и точный результат. Таким образом, перед анализом случайности идентификатора сеанса приложения рекомендуется иметь как минимум 1000–2000 пробных токенов.
Доступен ряд подразделов, которые могут помочь нам правильно проанализировать приложение, но, будучи пентестером, нам просто нужно проанализировать надежность результатов. Чтобы узнать больше можно ознакомиться с документацией.

Давайте нажмем кнопку «Save Tokens» и сохраним сгенерированные значения токенов в token.txt.
Пока файл сохраняется в фоновом режиме, давайте разлогинимся в bWAPP.

Теперь, при редиректе на страницу входа изменим внутри нее URL, установив:
http://192.168.0.9:8080/bWAPPИ зафиксируем текущий HTTP-запрос в нашем burpsuite.

Видим, что в заголовке файла cookie есть идентификатор сеанса.

Давайте изменим идентификатор сеанса с одним из наших сохраненных результатов.
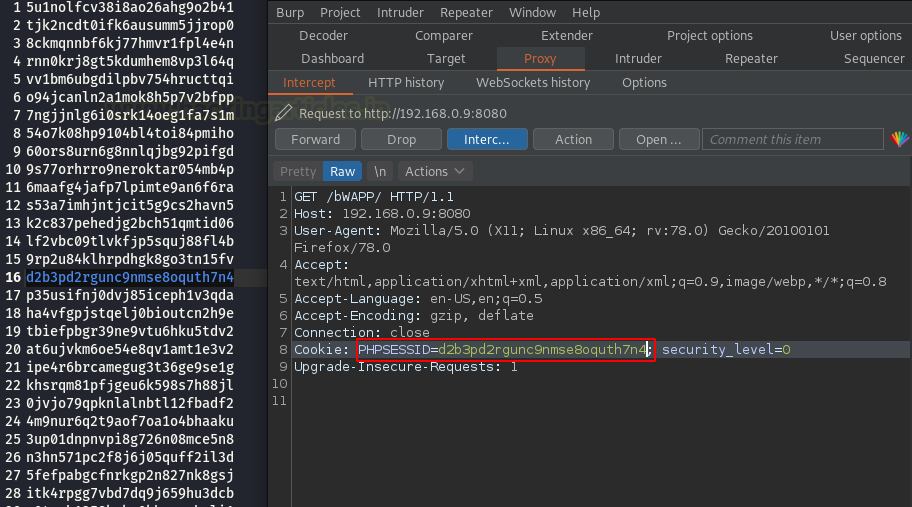
Как только мы нажимаем кнопку «forward», мы перенаправляется на страницу portal.php. Здесь также требуется идентификатор сеанса, поэтому повторяем наши манипуляции.

И когда мы снова нажимаем кнопку, в браузере мы вошли в систему как «Bee». На этот раз она была без учетных данных.
Бывают случаи, когда идентификатор сеанса, которым мы манипулируем, может быть недействительным, поэтому в таких случаях мы можем использовать весь tokens.txt c intruder для охоты за успешным входом в систему.
Ручной анализ запросов
Что, если у нас нет конкретного действующего веб-приложения, но у нас есть выборка токенов или идентификаторов сеансов, а мы хотим проанализировать или отобразить их случайность?
Независимо от того, взят ли образец из живого приложения или нет, секвенсор всегда готов выполнить статистический анализ, например, для определения случайности.
На панели инструментов перейдите на вкладку Sequencer к параметру Manal load, нажмите кнопку paste, если образец находится в вашем буфере обмена, или кнопку load, если токены находятся в определенном файле, а затем нажмите кнопку «Analyze now» для запуска секвенсора.
Выборка или количество токенов должно быть больше 100, чтобы можно было запустить ручной анализ.
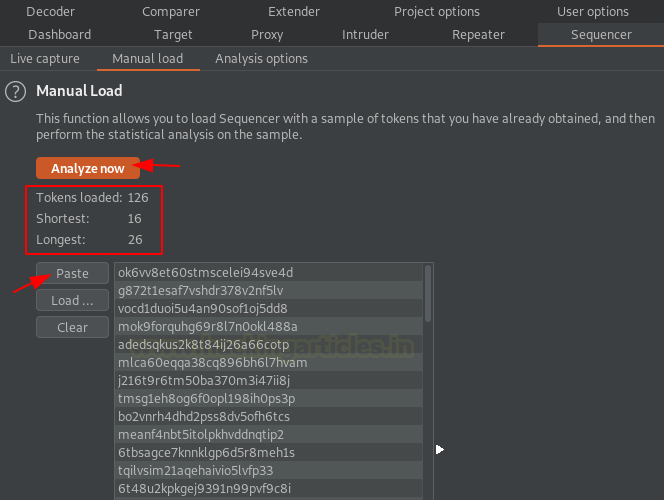
Через несколько секунд мы получаем результат, отображаемый в новом окне как «manual load analysis».
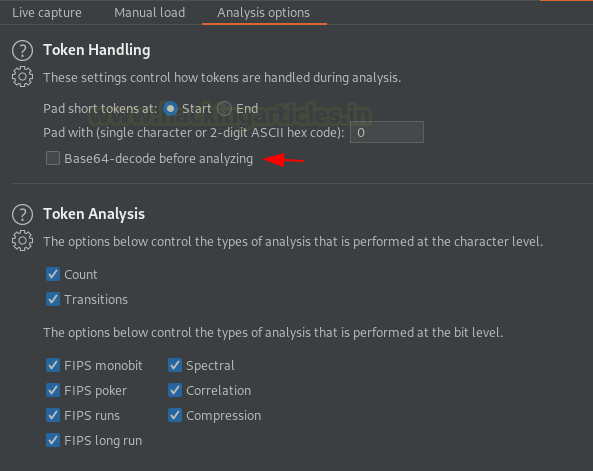
Если идентификатор сеанса или токен привязан к системе кодирования base64, тогда для таких случаев в секвенсоре есть специальная опция. В Sequencer’s dashboard переключаемся на вкладку параметров анализа и просто включаем «base-64 decode before analyzing».
Сравнение захваченных токенов
Burp Comparer – это инструмент для сравнения двух запросов или ответов друг с другом. Порой это помогает проще анализировать разные ответы.
Данный инструмент является наиболее дружелюбным, поскольку он работает почти со всеми другими разделами burp, такими как:
-
проксирование запросов
-
фаззинг с помощью Intruder
-
захват ответа с помощью Repeater
Будучи наиболее полезным, он имеет собственное место на панели burp.

Давайте воспользуемся инструментом Comparer с нашей вкладки Proxy и сравним два перехваченных запроса, захваченных в нем.
Просто нажимаем правой кнопкой мыши рядом с белым пространством захваченного запроса и отправляем его в Comparer.
Далее перехватите следующий запрос и снова отправим его.
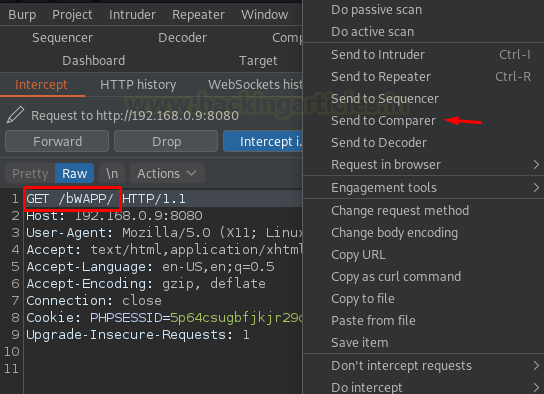
Теперь переключитесь на Comparer компаратора из панели, где мы увидим два наших запроса.
Мы даже можем вставить запрос или ответ прямо из нашего буфера обмена, нажав кнопку вставки. Также это можно сделать с помощью кнопки загрузки.
Вкладка «Сomparer» предлагает нам два варианта сравнения:
-
Пословное
-
Побитовое
Давайте начнем со слов.

Как только мы выбираем опцию сравнения, у нас появляется новое окно, в котором отображаются оба запроса и выделяются ключевые слова:
-
Modified
-
Deleted
-
Added
В правом нижнем углу есть флажок «Sync Views», который может помочь нам анализировать и прокручивать два запроса или ответа одновременно, если содержание в них немного длинное.
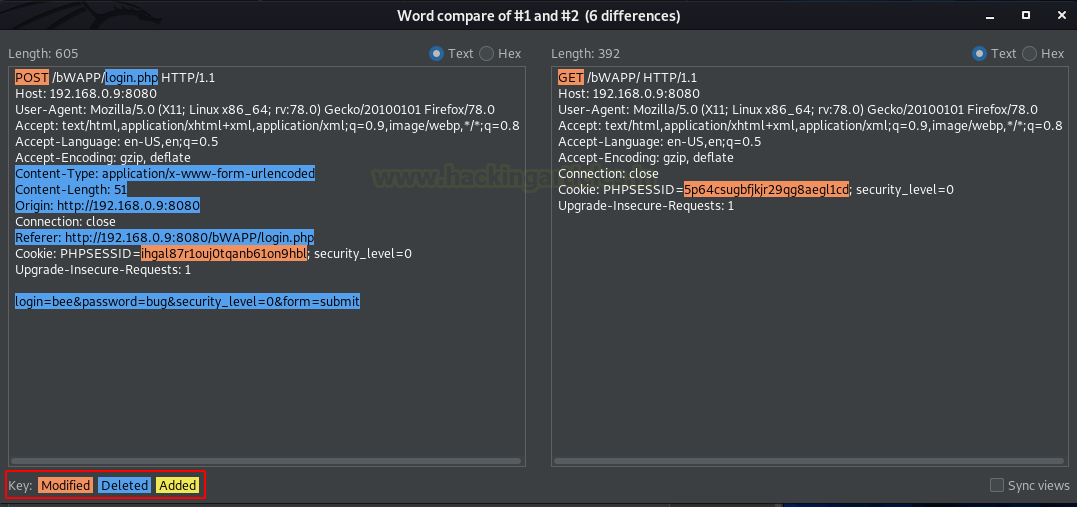
Из изображения выше мы можем определить, что идентификаторы сеанса уникальны и различаются во всем веб-приложении.
