Микрохирургия ELF’а или «А что, так можно было?!»
На Хабре есть множество статей на тему ELF – что только люди с ними не делают – объясняют их устройство, собирают вручную и автоматически, редактируют, шифруют и еще много чего. Я, в свою очередь, хотел бы поделиться интересным, на мой взгляд, кейсом, познакомившим меня сразу со многими аспектами низкоуровневого программирования на практике:
-
компиляция программ,
-
своеобразный реверс-инжиниринг и портирование runtime-библиотек,
-
устройство исполняемых файлов Windows и Linux,
-
сборка и редактирование таких файлов вручную
Эти и некоторые другие аспекты, а так же множество нестандартных ходов будут затронуты при портировании компилятора. При этом, часть работы, связанная с исполняемыми файлами (и ELF’ами в частности) показалась мне наиболее интересной, поэтому она и станет лейтмотивом статьи.
Эта статья не является исчерпывающим туториалом, но она может быть интересна читателям, интересующимся одной или несколькими областями выше и готовым открыть для себя (или освежить в памяти) не совсем стандартные подходы к решению задач в этих областях.
В ходе работы нам понадобятся:
-
компилятор gcc, линкер ld, отладчик gdb
-
утилиты из binutils (readelf, strip, hexdump)
-
базовое понимание устройства PE (Portable executable) и ELF
-
знакомство с Pascal и ассемблером
Компилятор
Компилятор, который мы хотим портировать называется Bero TinyPascal Compiler (далее, BTPC) был написан в 2016 году немецким программистом-музыкантом и энтузиастом Pascal, Бенжамином Россо (Benjamin Rosseaux). Он компилирует подмножество Pascal’я (Delphi 7-XE7 и FreePascal >= 3) в бинарный код Windows x32. К тому же, компилятор самоприменимый.
Проект доступен на github и сейчас репозиторий содержит почти все необходимые для работы над ним инструменты. Однако, на момент выполнения работы, репозиторий выглядел примерно так:
 и 1 бинарник")
Компилятор BTPC (и собранный из него btpc.exe) выполнен в self-contained виде – на все про все – один файл на ~3 тыс. строк паскаля. В нем представлен конвейер со всеми основными шагами компиляции – чтением входного потока, лексическим и синтаксическим анализом, генерацией промежуточного представления, генерацией кода. Поскольку, это не промышленный продукт, то никаких оптимизаций нет.
Начальные фазы разбора Pascal’я, вплоть до построения промежуточного кода, нас не очень интересуют – во-первых, это абсолютно типичные лексер и парсер, а во-вторых, они практически не будут изменены при портировании. Так что, примем их как данность. Наибольший интерес для нас представляет фаза синтеза и “все что после”.
Фаза синтеза или умышленное падение с Seg fault
Итог работы компилятора BTPC – исполняемый файл формата PE (Portable Executable, подробнее на Википедии или Mircosoft), т.е. “ELF для Windows”. В нем так же, как и в ELF, содержится все необходимое для отображения файла в память и запуска процесса, но организовано это все несколько иначе – отличия в основном касаются размещения в памяти.
Вот, что Википедия говорит о PE в 2х словах
Portable Executable (PE) — формат исполняемых файлов, объектного кода и динамических библиотек, используемый в Microsoft Windows. Формат PE представляет собой структуру данных, содержащую всю информацию, необходимую PE-загрузчику для отображения файла в память. Исполняемый код включает в себя ссылки для связывания динамически загружаемых библиотек, таблицы экспорта и импорта API-функций и т.д.
PE представляет собой модифицированную версию COFF формата файла для Unix. Основные «конкуренты» PE — ELF (используемый в Linux и большинстве других версий Unix) и Mach-O (используемый в Mac OS X).
Начнем рассмотрение фазы синтеза с момента, когда фронтенд уже выполнил свою часть, разобрав Pascal, и, когда у нас уже есть промежуточный код программы, байт-код:
-
каждой инструкции байт-кода компилятор ставит в соответствие набор ассемблерных инструкций
-
этот набор ассемблерных инструкций – по сути представление “бизнес-логики” программы в ассемблере
-
бизнес-логика “подкладывается” в некоторый существующий PE-файл
-
PE-файл редактируется, чтобы эта логика не “отвалилась” в процессе.
Концептуально это напоминает работу какого-нибудь фреймворка. Хотя фактически, это классическая библиотека времени выполнения (Runtime Library, RTL).
О Runtime Library в 2х словах
Пример RTL-библиотеки – CRT для C/C++. Функции такой библиотеки отвечают, например, за подготовку и освобождение стека вызовов, инициализацию переменных и т.д. Эти функции, как правило, нельзя вызвать самостоятельно из основной программы.
Самый простой пример – pre-start и post-exit “хуки”, срабатывающие до и после вызова main’а вашей программы. Они разбирают аргументы командной строки, вызывают конструкторы статических объектов, вызывают непосредственно main, а затем освобождают память (вызывая деструкторы), когда main возвращает управление.
Наш PE-файл содержит библиотеку RTL с реализацией 9 простых функций:
-
RTLHalt — остановка программы
-
RTLWriteChar — запись char’а в stdout
-
RTLWriteInteger — запись integer’а в stdout
-
RTLWriteLn — вывод linebreak’а в stdout
-
RTLReadChar — сохранение в EAX символа из STDIN
-
RTLReadInteger — сохранение в EAX integer’а из STDOUT
-
RTLReadLn — пропуск STDIN до EOF (конец файла) или ближайшего перевода строки
-
RTLEOF — возвращает в EAX положительное число в случае EOF. 0 — в противном случае.
-
RTLEOLN — устанавливает 1 в DL, если следующий символ – n, 0 — в противном случае
Технически – это ассемблерный файл с одной лишь секцией кода на пару сотен строк, со следующей структурой:
.ENTRYPOINT
JMP StubEntryPoint # точка входа тут же отправляет нас в конец файла
RTLHalt:
... # определение фукнции RTLHalt
RTLWriteChar:
...
... # опеределения остальных функций RTL
RTLFunctionTable: # таблица указателей на функции
DD OFFSET RTLHalt
DD OFFSET RTLWriteChar
DD OFFSET RTLWriteInteger
...
StubEntryPoint:
INVOKE HeapAlloc ... # резервирование памяти
MOV ESI, OFFSET RTLFunctionTable # сохранение таблицы функций
ProgramEntryPoint:Теперь, если скомпилировать и запустить приведенный выше RTL, происходит следующее:
-
входная точка программы отправляет нас на метку StubEntryPoint
-
резервируется память для будущей программы
-
таблица функций сохраняется в неизменяемый в процессе работы регистр ESI
-
управление передается программе
И …программа падает, ведь метка ProgramEntryPoint указывает в никуда!
Но, можно предположить, что BTPC умеет дописывать код компилируемой программы следом за меткой ProgramEntryPoint.
Предположение
В рамках статьи это кажется очевидным, но в тот момент у нас на руках было всего 2 файла – никаких инструкций или скриптов.
Их взаимодействие было не очень понятным: файлы btpc.pas и rtl.asm не имели никаких упоминаний друг друга и не были никак связаны. Но в файле btpc.pas был blob, который наталкивал на некоторые мысли:
{ фронтенд компилятора }
procedure EmitStubCode;
begin
OutputCodeDataSize := 0;
OutputCodeString(#77#90#82#195#66#101#82#111#94#102#114#0#80#69#0#0#76#1#1#0#0#0#0#0#...
OutputCodeString(#0#0#0#0#0#0#0#0#0#0#0#0#0#0#16#0#0#0#16#0#0#143##16#0#0#0#0...
OutputCodeString(#0#0#0#0#0#0#0#0#0#0#255#255#255#255#40#16#0#0#53#0#0#0...
OutputCodeString(#101#110#106#97#109#105#110#32#39#66#101#82#111#...
OutputCodeDataSize := 1423;
end;
{ бэкенд компилятора }Мысли оказались верными – внутри Pascal-кода компилятора находится сериализованная библиотека, полученная из rtl.asm.
Некоторое время спустя Бенджамин выложил собственные инструменты, которыми он собирал PE и внедрял в компилятор.
И кажется, теперь стала понятна и архитектура компилятора:
-
Библиотека RTL (с реализациями базовых функций) компилируется и дает нам исходный, готовый к работе PE-файл (хоть он и падает, но он чисто технически – рабочий)
-
Этот PE-файл сериализуется в паскаль-строки (те самые, с ограничением в 255 символов в длину)
-
Если кода меньше, то окончание добивается инструкциями-заглушками NOP
-
-
Эти паскаль-строки помещаются в качестве шаблона (набора констант) непосредственно в компилятор

Компилятор BTPC работает следующим образом:
-
Считывает программу из stdin
-
В процессе анализа генерирует промежуточный код программы, байт-код
-
В процессе синтеза, инструкциям байт-кода ставит в соответствие ассемблерные инструкции
-
Дописывает получающиеся инструкции в конец шаблона (сериализованного в паскаль-строки PE-файла)
-
Редактирует шаблон таким образом, чтобы загрузчик “увидел” новый, дописанный в конец, код компилируемой программы
-
Десериализует результат в исполняемый файл
Редактирование PE32
А вот и первая хирургическая операция: пациент – наш исполняемый файл в виде пачки паскалевских строк. Нам необходимо отредактировать опеределенные символы этих строк, в которых скрываются значения, считываемые загрузчиком. Очевидно, если промахнуться, то в лучшем случае ничего не произойдет (попали в неинициализированные данные или в пространство между секций). В худшем же случае мы потеряем пациента: загрузчик, считав неверное значение, либо зачерпнет лишнего, либо не загрузит необходимые данные.
Пример правильного патчевания: размер секции кода занимает 4 байта, начиная со 156 байта. При этом во время компиляции было сгенерировано 100 байтов кода. Тогда, необходимо извлечь значение из этих 4х байтов, прибавить к нему 100 и записать обратно.
Стоит отметить, что изначально для компиляции RTL, Бенджамин использовал свой собственный тулчейн Excagena, который во-первых собирает крайне минималистичный выходной PE-файл. Обычно компиляторы/линкеры добавляют отладочную информацию в выходной файл, но Excagena вырезает все, что не влияет напрямую на работу.
Во-вторых, секция кода находится в самом конце полученного PE. То есть, буквально, метка ProgramEntryPoint – последнее, что в нем есть.
Цель всего этого – облегчить последний этап – редактирование PE-файла. И Бенджамину это вполне удалось – от него требуется лишь обновить пару значений в общей структуре:
-
размер кода (OptionalHeader.SizeOfCode)
-
размер секций (SectionTable.VirtualSize)
-
размер образа (OptionalHeader.SizeOfImage), загруженного в память
Так что вся его хирургия выглядит вполне компактно – он считывает предыдущее значение поля, корректирует его с учетом добавленного фрагмента и выравнивания, и записывает обратно по прежнему адресу:
{ Вычисление размера кода }
CodeSize := OutputCodeGetInt32($29) + (OutputCodeDataSize - CodeStart);
OutputCodePutInt32($29, CodeSize);
{ Определение текущего значения выравнивания }
SectionAlignment := OutputCodeGetInt32($45);
{ Вычисление и редактирование виртуального размера секции с учетом выравнивания }
SectionVirtualSize := CodeSize;
Value := CodeSize mod SectionAlignment;
SectionVirtualSize := SectionVirtualSize + (SectionAlignment - Value);
OutputCodePutInt32($10d, SectionVirtualSize);
{ Редактирование размера образа при загрузке в память }
OutputCodePutInt32($5d, SectionVirtualSize + OutputCodeGetInt32($39));Хотя общая идея сейчас ясна, магическим $29, $45, $115 в оригинальном коде не помешали бы имена…
Портирование компилятора
Мы разобрались с устройством компилятора, но наша конечная цель – получить работающий под Linux x64 компилятор. Чтобы ее достичь, понадобится выполнить следующее:
-
переписать RTL библиотеку с использованием системных вызовов Linux x64
-
собрать из нее исходный ELF-файл
-
научиться динамически редактировать ELF-файл, дополненный кодом
Всего-то 3 шага

Первый эта достаточно простой – нужно “лишь” заменить системные вызовы к WinApi на линуксовые.
Но, как всегда, просто было на бумаге. Для примера можно взять вспомогательную функцию чтения символа. Устройство функции достаточно простое – подготовка регистров, обращение к Win32 API, установка еще пары значений:
ReadCharBuffer: DB 0x90
ReadCharBytesRead: DB 0x90,0x8D,0x40,0x00
ReadCharEx:
PUSHAD
INVOKE ReadFile, DWORD PTR StdHandleInput, OFFSET ReadCharBuffer, 1, OFFSET ReadCharBytesRead, BYTE 0
TEST EAX, EAX
SETZ AL
OR BYTE PTR IsEOF, AL
CMP DWORD PTR [ReadCharBytesRead], 0
SETZ AL
OR BYTE PTR IsEOF, AL
POPAD
RETКак упоминалось ранее, секция кода у нас единственная, при этом она и исполняемая и перезаписываемая. Причина в том, что среди кода хранятся и данные – в данном случае “между функций” приталились несколько байт под буферы чтения – ReadCharBuffer и ReadCharBytesRead. Пожалуй, мы знаем причину этого…

Но наша задача – не просто скопировать, но и улучшить новую версию, если это возможно. В соответствии с правилами секционирования (глобальные данные – в секциях с правами чтения и записи, константы – в секциях с правами чтения и запретом записи, код – с правами чтения и выполнения), поделим наш монолитный код на секции.
Напомню, что в 64-битных системах системные вызовы совершаются инструкцией syscall (хотя это и не единственный способ). Аргументы передаются через регистры по порядку, RDI, RSI, RDX и так далее. Результат возвращается через RAX.
В x64 исчезли аналоги pusha, pushad, popa, popad. В качестве замены введем свои макросы pushall, popall, работающие аналогично. Поместим эти макросы в секцию неинициализированных данных – bss.
В свою очередь, буферы уходят в секцию данных – data.
В итоге описанная выше функция принимает вид:
.section .data # буфер чтения - в секции данных
ReadCharBuffer:
.byte 0x3c
.section .text # код - в секции кода
ReadCharEx:
PUSHALL # макрос - в секции bss
XORQ %RAX, %RAX # syscall #0: read(int fd, void *buf, size_t count)
XORQ %RDI, %RDI # fd : 0 == stdin
MOVQ $ReadCharBuffer, %RSI # buf : ReadCharBuffer
MOVQ $1, %RDX # count : 1 byte
SYSCALL
CMPQ $0, %RAX
SETZ %BL
ORB %BL, (IsEOF)
POPALL
RETСледующее, что делал Бенджамин после заполнения таблицы указателей на функции – резервировал стек. В нашем случае для резервирования можно было бы пройти с некоторым шагом по стеку, записывая какие-нибудь значения, пока не встретится Guard Page.
Однако, выяснилось, что Linux для каждого запущенного процесса запоминает список регионов виртуальной памяти и, в случае ошибки обращения, проверяет, не произошел ли Segmentation fault. Если не произошел, значит было обращение к неинициализированной странице, а значит необходимо лишь выделить еще одну страницу виртуальной памяти и добавить к региону. Получатся, резервировать память заранее не требуется. В вот столкнуться с Guard Page в принципе непростая задача. Значит, необходимость в подготовке стека в новой библиотеке отпала, что для нас, конечно же, плюс.
Осталось скомпилировать и слинковать библиотеку:
$ gcc -c rtl64.s
$ ld rtl64.o -g --output rtl64Полученный ELF сериализуем в паскаль-строки и помещаем в BTPC вместо прежнего шаблона. На этом библиотеку можно считать портированной.
Кодогенерация
Как мы уже видели, BTPC в процессе компиляции переводит байт-код в ассемблерные инструкции и конкатенирует их с шаблоном процедурами EmitByte:
procedure OCPopESI;
begin
EmitByte($5e);
LastOutputCodeValue := locPopESI;
end;
procedure OCMovzxEAXAL;
begin
EmitByte($0f);
EmitByte($b6);
EmitByte($c0);
LastOutputCodeValue := locMovzxEAXAL;
end;Нам, в свою очередь, придется подбайтово записывать инструкций из набора x64. Это можно сделать двумя способами – либо вручную, либо немного схитрить и упростить себе жизнь
Способ 1 – хардкорный перевод вручную
Переведем вручную инструкцию MOV R10, [R12 + R13], (напомню, квадратные скобки обозначают взятие значения по адресу) воспользовавшись материалами методички “Intel 64 and IA-32 Architectures Developer’s Manual”

-
Переводим номера операндов в двоичный вид. Регистр-приемник – R10 подходит под формат “R?”.
-
Находим инструкцию MOV в таблице кодов инструкций i8086+. Нужен формат “r/m →R?”. Итого, получаем 0x8B.
-
Операнд R10 в двоичном представлении имеет длину 4 бита, а значит не входит в отведенные 3 бита Rn байта ModR/M.
-
Для представления подобных “больших” регистров понадобится байт “Префикс REX”.
-
Старший бит R10 уходит в бит R префикса REX и расширяет Rn в байте ModR/M.
-
Согласно таблице ModR/M для 32-разрядных инструкций, биты R/M байта ModR/M = 100, а биты Mod = 00. Это дает дополнительный байт SIB.
-
Старший бит регистра R12, равный 1, взводит бит X в префиксе REX и расширяет номер индекса в SIB.
-
Байт SIB выглядит, как [#Base + #Index2^(Scale)]. Базу Base образует регистр R12. 3 младших его бита = 100 и устанавливаются на место 3х битов Base в SIB.
-
Индекс(Index) в SIB составляют 3 младших бита регистра R13 = 101.
-
Так как в инструкции лишь сложение (1 регистр + 1 регистр), биты Scale в байте SIB = 00 и дают 2^(Scale) = 2^0 = 1.
-
Старший бит регистра R13 уходит в бит B префикса REX. Это расширяет набор базового регистра в байте SIB.
-
Конкатенируем байт префикса REX: “0100” + “W:1” + “R:1” + “X:1” + “B:1” = 01001111, что в hex записи дает 0x4F. Префикс REX найден.
-
Конкатенируем байт ModR/M: “Mod:00” + “Rn:010” + “R/M:100” = 00010100, что дает байт 0x14.
-
Конкатенируем наконец байт SIB: “Scale:00” + “Index:101” + “Base:100” = 00101100, что дает байт 0x2C.
Путем конкатенации полученных байтов имеем инструкцию MOV R10, (R12 + R13) в виде 0x4F 0x8B 0x14 0x2C .
Мы уже видели, как происходит хирургическая операция над PE-файлом и делать еще одну операцию, взводя и обнуляя биты, совсем не хочется. Тем более, что таких инструкций в BTPC около 70 штук.
Мы же сразу перейдем к упрощенному способу: надо лишь приготовить все нужные нам инструкции, скомпилировать, а затем дизассемблировать полученный файл и достать нужные нам байты.
Осталось заменить в коде выше значения байтов и на этом этап кодогенерации можно считать завершенным.
Хирургическая операция над ELF’ом
Очевидно, код, который BTPC генерирует сейчас – невидим для исполняемого файла, ведь он дописывается даже не в конец, а “после” файла, то есть, грубо говоря, лежит рядом. При этом генерируемый код конситентен с уже существующим.
Для нас это означает то, что настал шаг, которого мы ждали и боялись – микрохирургия ELF’а – будем пришивать хвост живому эльфу код рабочему ELF’у.
Но для начала оценим, насколько все плохо. Опасение вызывают 2 факта:
-
ELF64 отличается от PE32
-
PE32 был собран вручную, с некоторыми хаками
Воспользуемся readelf’ом и прочтем собранный ранее rtl64:
$ readelf --section-headers rtl64
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .text PROGBITS 00000000004000b0 000000b0
0000000000000317 0000000000000000 AX 0 0 1
[ 2] .data PROGBITS 00000000006003c7 000003c7
00000000000000bf 0000000000000000 WA 0 0 1
[ 3] .symtab SYMTAB 0000000000000000 00000488
0000000000000408 0000000000000018 4 39 8
[ 4] .strtab STRTAB 0000000000000000 00000890
0000000000000248 0000000000000000 0 0 1
[ 5] .shstrtab STRTAB 0000000000000000 00000ad8
0000000000000027 0000000000000000 0 0 1Чуда не случилось – в нашем ELF’е аж 6 секций!:
-
нулевая пустая секция (согласно стандарту)
-
секция кода — text
-
секция данных — data
-
секция имен секций — shstrtab (Section header string table)
-
таблица символов в symtab
-
метки из ассемблерного ассемблерного кода в strtab

Чем ближе секция кода к концу файла, тем лучше для нас. Нам не повезло от слова совсем – секция кода плотно зажата данными и метаданными. Если мы сейчас найдем метку ProgramEntryPoint и пойдем записывать код после нее, мы с большой вероятностью “потеряем пациента”.
Откуда столько секций? Мы ведь компилировали лишь код и данные. Получается, они подтянулись на стадии линковки и наш файл стал весить почти 4 Кб, а там ведь всего пара сотен строк кода, не считая внутренностей самого ELF’а.
Попросим ld не включать ничего лишнего (–nostdlib, –strip-all):
$ ld rtl64.o -g --output rtl64-min -nostdlib --strip-allELF сжался в 2 раза – теперь весит всего 1.4 Кб. Взглянем еще раз на секции:
$ readelf --section-headers rtl64-min
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .text PROGBITS 00000000004000b0 000000b0
0000000000000317 0000000000000000 AX 0 0 1
[ 2] .data PROGBITS 00000000006003c7 000003c7
00000000000000bf 0000000000000000 WA 0 0 1
[ 3] .shstrtab STRTAB 0000000000000000 00000486
0000000000000017 0000000000000000 0 0 1Минус 2 секции. Уже лучше, хотя shstrtab все еще на месте. Вспоминаем, что в комплекте binutils есть утилита strip, которая умеет редактировать исполняемые файлы. Пробуем вырезать shstrtab из нашего файла и снова прочесть оставшиеся секции:
$ strip -R shstrtab rtl64-min
$ readelf --section-headers rtl64-min
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .text PROGBITS 00000000004000b0 000000b0
0000000000000317 0000000000000000 AX 0 0 1
[ 2] .data PROGBITS 00000000006003c7 000003c7
00000000000000bf 0000000000000000 WA 0 0 1
[ 3] .shstrtab STRTAB 0000000000000000 00000486
0000000000000017 0000000000000000 0 0 1Shstrtab и ныне там. Посмотрим, что же внутри:
$ hexdump -C rtl64-min
00000480 40 00 00 00 00 00 00 2e 73 68 73 74 72 74 61 62 |@.......shstrtab|
00000490 00 2e 74 65 78 74 00 2e 64 61 74 61 00 00 00 00 |..text..data....|
000004a0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|В секции с именами секций лежат …имена секций! Хотя бы здесь все предсказуемо. Оказывается, что секция .shstrtab всегда генерируется при линковке. Хотя, согласно спецификации, для исполнения она не нужна – то есть, теоретически избавиться от нее возможно.
Но так или иначе, заветная секция кода все еще прикрыта секцией данных (мы сами решили привести секции в порядок). Попробуем поменять их местами. Для этого отредактируем линковочный скрипт так, чтобы код был в конце.
Концептуально, минималистичный скрипт линкера выглядел бы для нас следующим образом:
ENTRY(_start) /* точка входа */
SECTIONS
{
. = 0x4000b0; /* адрес размещения секции данных */
.data : { *(.data) }
.bss : { *(.bss) *(COMMON) }
. = 0x6000d3; /* адрес размещения секции кода */
.text : { *(.text) } /* секция кода идет последней в файле */
}В реальности скрипт ld занимает две сотни строк – приводить его здесь не имеет смысла. Интересующиеся, однако, могут воспользоваться командой ld --verbose – выглядит этот скрипт довольно пугающе, но найти блок, отвечающий за размещение секции кода все же можно. Перемещаем этот блок в самый конец.
Теперь у нас имеется специальный скрипт линковки. Воспользуемся им и вновь прочтем секции:
$ ld rtl64.o -g --output rtl64-custom-ld -T linkerScript.ld -nostdlib --strip-all
$ readelf --section-headers rtl64-custom-ld
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .data PROGBITS 00000000006000b0 000000b0
00000000000000bf 0000000000000000 WA 0 0 1
[ 2] .text PROGBITS 0000000000a00170 00000170
0000000000000317 0000000000000000 AX 0 0 1
[ 3] .shstrtab STRTAB 0000000000000000 00000487
0000000000000017 0000000000000000 0 0 1Бинго, скрипт сработал! Секция text, действительно, поменялась местами с секцией data.
Однако, кажется, мы выстрелили себе в ногу. До этого мы могли отлаживать процесс старым добрым gdb, но сейчас из-за того, что мы вырезали и таблицы символов, и метки в коде, и всю отладочную информацию, отлаживать стало просто невозможно.
Хотя ранее по соседству содержались и код и данные, так что некоторые команды из-за этого неверно отображались в gdb и запутаться было крайне легко. Как с этим всем справился Бенджамин, история умалчивает…
Мы же, поняв, что погорячились, возвращаем секции symtab и strtab на место, убрав опции линкера. И вот, у нашей реализации появилось преимущество над оригиналом – несравнимо более удобный для отладки код – в нем только актуальные команды (все отображается корректно, т.к. не перемешано с данными) и в нем есть отладочные символы
Тем не менее, код все еще зажат в глубине файла. Кажется, пришло время волевым решением разрезать файл напополам, вставить в середину код и склеить обратно. Мой аналогичный вопрос на stackoverflow был, мягко скажем, воспринят неоднозначно. Но мы будем проделывать этот процесс при каждой компиляции:
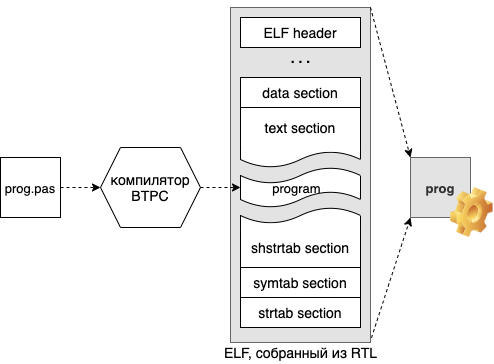
Тогда, чтобы добиться работспособности файла, необходимо отредактировать поля следующих структур:
|
Название поля |
Смещение до поля |
|
Elf__hdr.e__shoff |
0x28 |
|
Text_phdr.p_filesz |
sizeof(Elf__hdr) + sizeof(p_hdr) + 0x20 |
|
Text_phdr.p_memsz |
sizeof(Elf_hdr) + sizeof(p_hdr) + 0x28 |
|
Text_shdr.sh_size |
Elf_hdr.e_shoff + sizeof(injection) + 2*sizeof(s_hdr) + 0x20 |
|
Shstrtab_shdr.sh_offs |
Elf_hdr.e_shoff + sizeof(injection) + 3*sizeof(s_hdr) + 0x18 |
|
Symtab_shdr.sh_offs |
Elf_hdr.e_shoff + sizeof(injection) + 4*sizeof(s_hdr) + 0x18 |
|
Strtab_shdr.sh_offs |
Elf_hdr.e_shoff + sizeof(injection) + 5*sizeof(s_hdr) + 0x18 |
Приведенные выше значения надо увеличить на размер сгенерированного кода: sizeof(injection). Значения учитывают порядок размещения секций в файле.
Внимательный читатель заметит, что после того, как мы научились редактировать ELF’ы, можно не утруждаться перемещением секций – ведь теперь, где бы ни хранился код, мы сможем до него добраться, не сломав все вокруг.
И, поскольку теперь мы знаем, где “резать”, где “пришивать” и куда “колоть”, реализовать эти функции в компиляторе не составит труда.
На этом процесс разработки можно считать завершенным. Теперь, у нас генерируется ELF, мы проводим над ним операцию, которая на проверку оказалась не такой и страшной. Осталось лишь итеративно отладить результаты компиляции – начать с самых простых однострочных программ и постепенно их усложнять. В качестве образца берем исходный компилятор и ожидаем, что для одной и той же программы наш новый компилятор выдаст нам файл с идентичными инструкциями с точностью до разрядности и деталей портирования RTL.
Через несколько итераций получаем работоспособный компилятор.
Еще через несколько – выполняем bootstrapping
# Получаем кросскомпилятор
$ btpc.exe < btpc64.pas > btpcCrossWin.exe
# Еще шаг и получаем его Linux–версию
$ btpcCrossWin.exe < btpc64.pas > btpc64Linux
# Еще один, «контрольный» шаг, уже на Linux
$ btpc64Linux < btpc64.pas > btpc64CheckКомпилятор раскручен
И в конце концов получаем самоприменимый компилятор подмножества Pascal, работающий под Linux x64, как и было запланировано.
Заключение
Теперь, когда мы выполнили поставленную задачу, можно оглянуться и подвести итоги. Вот что мы сделали:
-
разобрались с архитектурой компилятора BTPC
-
Выяснили, как устроен процесс от исходного кода на Pascal до исполняемого файла Windows
-
Пересобрали библиотеку времени выполнения (RTL)
-
Собрали из RTL файл ELF и разобрались в его внутреннем устройстве и научились динамически его редактировать
-
Исправили процесс кодогенерации
-
Собрали полученное в рабочий компилятор
Результаты работы доступны в репозитории на github.
Если Вы дочитали до этого момента, то, надеюсь, не жалеете о потраченном времени. Надесюь, что Вы открыли для себя что-то новое. Но, даже если Вас ничего не удивило, возможно вы освежили знания
P.S.
Наверняка, многие уже догадались, что задача походит на учебный проект. Это, действительно, курсовая работа по компиляторам на кафедре ИУ9 в МГТУ им. Баумана, которую я выполнил несколько лет назад. Предстоящий объем работы казался тогда невыполнимым. И чем больше работы было проделано, тем, казалось, больше работы предстоит впереди. Но процесс и достигнутый результат оказались более занимательным, чем шаги в неизвестность (и возгласы “а так можно было?”) на каждом этапе работы. И вот, спустя несколько лет, у меня дошли руки написать краткую статью о проделанной тогда работе, попытавшись сохранить интересные и важные “открытия”, сделанные в ходе нее, и опустив лишние технические детали (“невошедшее” можно найти в отчете в репозитории выше).
Также, не могу не поблагодарить своего научного руководителя, Александра Коновалова.
Как отмечалось в начале, эта статья не ставила целью объяснить устройство ELF, научить выполнять безбашенные трюки над ними, или же портировать программы. Но на реальном примере она, надеюсь, показала, какими нестандартными бывают решения обычных задач, какие интересные вещи можно наблюдать в ходе их решения и какие открытия для себя делать… И, быть может, она сподвигнет кого-нибудь сделать первый шаг навстречу следующей неизведанной, но захватывающей задаче…