Мониторинг с высокой доступностью. Опыт компании СберСервис
СберСервис – крупнейшая сервисная компания федерального значения, оказывающая услуги по комплексному техническому обслуживанию широкого спектра информационно-телекоммуникационного оборудования, рабочих мест, офисной техники, серверов и телефонии. Компания является единственным на территории СНГ премиум-партнером компании Zabbix, в ней работает самая крупная команда в России в сфере ИТ-мониторинга, разрабатывая уникальные технические решения в области комплексного внедрения систем мониторинга для организаций с высоконагруженной ИТ-инфраструктурой. Данный факт объясняет, почему в качестве основной платформы для мониторинга СберСервис выбирает Zabbix.
О чем эта статья?
Как следует из названия, в статье предлагается концепция организации мониторинга с высокой доступностью. В роли «подопытного» выступает Zabbix Server, для организации Active-Active кластера применяется Corosync и Pacemaker, а работает это всё на Linux. Данное ПО является OpenSource, поэтому такое решение доступно каждому.
В процессе эксплуатации Zabbix для мониторинга высоконагруженной ИТ-инфраструктуры (рост количества элементов данных, рост числа узлов сети, большая глубина хранения сырых данных, постоянно растущие потребности пользователей) многие сталкиваются с проблемами производительности сервера Zabbix во время старта или перезапуска. В условиях High Load (>60k NVPS) обычная перезагрузка сервера Zabbix превращается в весьма длительную, хотя и штатную процедуру. Время от запуска службы до появления данных в мониторинге может достигать 15-20 минут.
Столкнувшись с этим, и проанализировав ситуацию, команда мониторинга пришла к решению, что поможет кластеризация по принципу Active-Active. Кроме того, была поставлена цель добиться Disaster Recovery путем переноса на разные ЦОДы.
Задача
Создание отказоустойчивого, высокодоступного двухплечевого кластера Zabbix-сервера, работающего в режиме Active-Active и обеспечивающего непрерывность управления, записи, а также исключающего возможность дублирования информации при записи в базу данных.
Существует множество схем и способов как обезопасить сетевую среду сервиса от падения. Команда решила идти по пути адаптации мощной и высоконагруженной системы мониторинга Zabbix к аппаратным и программным возможностями кластеризации, существующим на рынке ИТ-сферы, СберСервис создал кластер высокой доступности. Выбор пал на OpenSource-решения, а точнее на Pacemaker и Corosync.
Требования
При создании кластера необходимо учесть два важных критерия:
-
управление нодами ZabbixServer без видимого прерывания сервиса мониторинга на время проведения различных технических работ по обновлению, правке конфигураций и т. д., именно поэтому не подойдет виртуализация в чистом виде;
-
бесшовное переключение трафика между инстансами ZabbixServer в случае выхода из строя одной из нод, желательно автоматически.
Встроенный функционал схемы кластеризации ресурсов в режиме Active-Passive с использованием Pacemaker и Corosync рассматривался уже много раз и в частности на Хабре есть подробная статья для случая кластеризации БД и статья про кластеризацию Заббикса (вместо Corosync использовался cman, но смысл тот же).
Как уже упоминалось выше, применительно к системе мониторинга на базе Zabbix данное решение попросту не подходит, если у вас «Большой мониторинг», так как во время старта инстанса ZabbixServer выполняется проверка и применение конфигурации сервера, выделения памяти, кэша, запуск заданного количества различных подпроцессов – и все эти предпусковые задачи составляют львиную долю времени для полноценного запуска системы. А это время фактического простоя мониторинга, отставание данных и заполнение кэшей.
Команда смогла придумать схему и реализовать логику работы всех компонентов и модулей системы для воплощения в реальность отказоустойчивого кластера, работающего в режиме Active-Active как с применением в схеме аппаратного балансировщика нагрузки (LoadBalancer), так и без него.
Полученное решение реализует два важных для системы мониторинга свойства:
-
Непрерывность мониторинга
-
Отказоустойчивость мониторинга
Рассмотрим реализацию решения High Available ZabbixServer в режиме Active-Active без LoadBalancerПринципиальная схема взаимодействия компонентов:

Принцип работы
Использование в схеме «менеджера управления кластерными ресурсами» (Cluster resource) подразумевает развертывание компонентов управления кластером на виртуальном сервере. Таким образом достигается отказоустойчивость управляющего модуля.
В кластере существует 2 ноды. При подготовке нод следует учитывать свойства stonith и quorum — их необходимо отключить.
Свойство quorum применяется для схемы кластера от 3х нод и более. Если в схеме кластера, состоящего из 2х нод использовать данное свойство, тогда при «падении» одной ноды произойдёт выключение всех ресурсов.
Свойство stonith обеспечивает принудительное завершение рабочих процессов на серверах, которые в свою очередь не смогли самостоятельно их завершить. К вышедшей из строя ноде запросы поступать не будут, т. к. она изолируется до тех пор, пока не выйдет из аварийного состояния с отправкой сообщения о том, что нода снова в рабочем состоянии.
В каждой ноде создаются кластерные ресурсы:
ocf::heartbeat:ZBX-IPaddress
ocf::heartbeat:ZBX-InstanceПри аварийном выходе из строя основной ноды, кластерные ресурсы перемещаются на резервную ноду. Ресурс ZBX-IPaddress управляет виртуальным ip-адресом и входит в стандартный набор кластерных ресурсов (IPaddr2). ZBX-Instance — самописный кластерный ресурс для сервиса zabbix-server и управления подключениями к БД. На каждом Zabbix-сервере в конфигурационном файле прописаны разные пользователи БД, при этом, в любой момент времени пользователь основного Zabbix-сервера имеет права Read/Write, а пользователь резервного права ReadOnly, поэтому на обеих нодах служба zabbix-server может находиться в запущенном состоянии (привет, Active-Active).
Перевод кластерных ресурсов в случае сбоя выглядит следующим образом. Ресурс ZBX-IP-address переводит виртуальный IP-адрес на другую ноду, а ресурс ZBX-Instance переводит пользователя БД резервного zabbix-сервера в режим Read/Write, а пользователя БД основного zabbix-сервера в режим ReadOnly, при этом закрывая имеющиеся к БД старые сессии подключения. Таким образом мониторинг инфраструктуры не прекращается. Непрерывность записи информации достигается за счет буферизации снятых метрик с объектов мониторинга на стороне ZabbixProxy. После того как прокси получает подключение к серверу, он передает накопленные данные.
Важный нюанс — применение данной схемы подходит только в случае нахождения master и slave ZabbixServer-нод в одной подсети.
Рассмотрим реализацию решения High Available ZabbixServer в режиме Active-Active с LoadBalancer
Принципиальная схема взаимодействия компонентов:
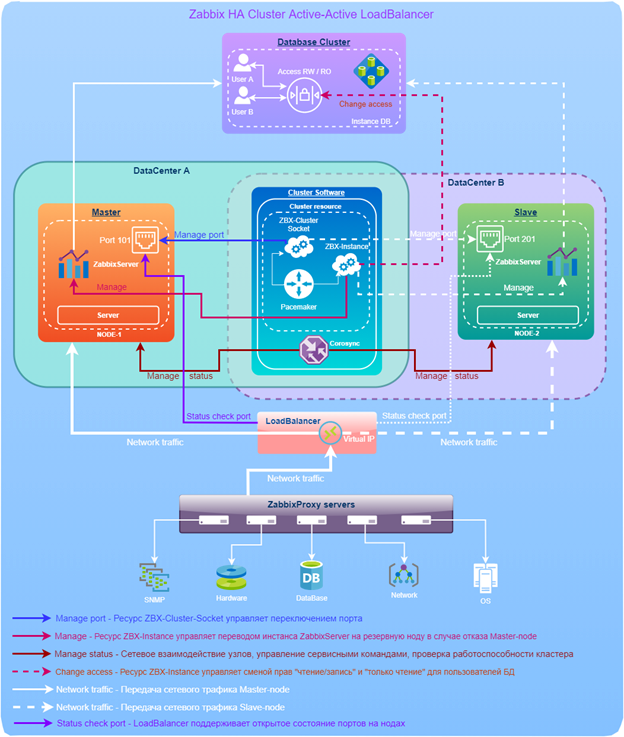
Принцип работы
Решение с применением аппаратной балансировки сетевой нагрузки на основе «сигнального порта» выглядит следующим образом. Аппаратный балансировщик нагрузки отправляет трафик на ноду, на которой доступен «сигнальный порт», если порт доступен на обеих нодах, LoadBalancer не будет отправлять трафик на какую-либо из нод. Решение можно использовать, когда ноды кластера находятся в разных подсетях, что позволило развернуть высокодоступный кластер для работы в «географически распределенном ЦОД».
В Pacemaker создаются кластерные ресурсы:
ocf::heartbeat:ZBX-Cluster-Socket
ocf::heartbeat:ZBX-InstanceРесурс ZBX-Cluster-Socket — управляет «сигнальным портом» на ноде — нужен для работы LoadBalancer-а.
Ресурс ZBX-Instance управляет процессом zabbix-server-а и правами доступа к БД.
Принцип работы данной схемы похож на схему «без аппаратного балансировщика нагрузки», но имеет ряд особенностей.
Ресурс ZBX-Cluster-Socket создаётся с помощью встроенной в Pacemaker функциональности по созданию ресурсов из системного процесса (службы). Служба «сигнального порта» — обыкновенная самописная служба, которая просто открывает на хосте соответствующий порт, за состоянием которого будет наблюдать LoadBalancer. Осуществлена «привязка» ресурса ZBX-Cluster-Socket к ресурсу ZBX-Instance посредством ограничения (constraint) для того, чтобы кластерные ресурсы «перемещались» совместно. Corosync, управляя ресурсом ZBX-Cluster-Socket, поддерживает в открытом состоянии только порт 101 на основной Master-node и в закрытом состоянии порт 201 на резервной Slave-node. Для LoadBalancer сигналом на переключение/отправку трафика являются: открытый порт 101 — на первой ноде или открытый порт 201 — на второй ноде, если оба порта на обеих нодах открыты, или оба закрыты, трафик никуда не отправляется.
Переключение ресурсов с текущей Master-node на текущую Slave-node происходит следующим образом:
При падении Master-node, порт 101 становится недоступным, тогда сигналом для LoadBalancer на переключение трафика будет являться открытый порт 201 на Slave-node. Corosync, определив, что Master-node недоступна, переключает ресурсы ZBX-Instance и ZBX-Cluster-Socket вместе на Slave-node, а благодаря скрипту «resource_movement», на основе которого Pacemaker создал ресурс ZBX-Instance происходит смена прав пользователей User_A и User_B в базе данных, при этом закрываются все старые сессии подключения к БД.
Что произойдет в случае потери связности между нодами кластера при условии полной работоспособности нод?
Схема та же: кластер состоит из 2-х нод Master-node (пользователь User_A) и Slave-node (User_B), на Master-node запущены кластерные ресурсы.
При потере связи каждая из нод определит, что другая нода недоступна, тогда обе запустят у себя кластерные ресурсы. Master-node перезапускать ничего не будет и продолжит работу, определяя свою роль главной. Slave-node тоже посчитает себя главной и запустит у себя кластерные ресурсы. При этом LoadBalancer определит, что на Master-node и Slave-node доступны порты ZabbixServer и управляющий порт, соответственно LoadBalancer прекратит передачу сетевого трафика.
Следует отметить важный момент — какими будут права доступа к базе данных соответствующих пользователей? Одна из нод по-прежнему будет иметь доступ к БД с правами Read/Write, а другая с правами ReadOnly, так как:
-
Если связь Slave-node с БД не была потеряна, то Slave-node во время включения у себя кластерных ресурсов произведет смену прав пользователей: для User_A права изменятся на ReadOnly, а для User_B права изменятся на Read/Write.
-
Если связь Slave-node с БД потеряна, следовательно Slave-node не сможет выполнить переключение прав пользователей.
-
После восстановления связности кластерные ресурсы снова «переместятся» на Master-node, LoadBalancer определит, что управляющий порт доступен только на Master-node и начнёт передавать ей сетевой трафик.
Заключение
Данный кейс иллюстрирует принципиальную идею и концепцию придуманного решения (а точнее 2-х реализаций), и не является прямым руководством к действию. Инфраструктуры и ограничения у всех разные, а инженеры, перед которыми ставятся похожие задачи не нуждаются в «How to».
В заключение стоит добавить, что в современном мире технологий нет почти ничего невозможного. Необходимы лишь желание и ресурсы.