[Перевод] Мы отрендерили миллион страниц, чтобы понять, из-за чего тормозит веб

- Посещён 1 миллион страниц
- Записано по 65 метрик каждой страницы
- Запрошен 21 миллион URL
- Зафиксировано 383 тысячи ошибок
- Сохранено 88 миллионов глобальных переменных
Можно ли превзойти наш анализ? Мы опубликовали наш набор данных на Kaggle, поэтому вы можете обработать данные самостоятельно.
Сегодня распространено мнение о том, что веб почему-то стал более медленным и забагованным, чем 15 лет назад. Из-за постоянно растущей кучи JavaScript, фреймворков, веб-шрифтов и полифилов, мы съели все преимущества, которые даёт нам увеличение возможностей компьютеров, сетей и протоколов. По крайней мере, так утверждает молва. Мы хотели проверить, правда ли это на самом деле, а также найти общие факторы, которые становятся причиной торможения и поломок сайтов в 2020 году.
Общий план был простым: написать скрипт для веб-браузера, заставить его рендерить корневую страницу миллиона самых популярных доменов и зафиксировать все мыслимые метрики: время рендеринга, количество запросов, перерисовку, ошибки JavaScript, используемые библиотеки и т.п. Имея на руках все эти данные, мы могли бы начать задаваться вопросами о том, как один фактор корреллирует с другим. Какие факторы сильнее всего влияют на замедление рендеринга? Какие библиотеки увеличивают время до момента возможности взаимодействия со страницей (time-to-interactive)? Какие ошибки встречаются наиболее часто, и что их вызывает?
Для получения данных достаточно было написать немного кода, позволяющего Puppeteer управлять по скрипту браузером Chrome, запустить 200 инстансов EC2, отрендерить миллион веб-страниц за пару выходных дней и молиться о том, что мы действительно правильно поняли ценообразование AWS.

Протокол, используемый для корневого HTML-документа
HTTP 2 сейчас более распространён, чем HTTP 1.1, однако HTTP 3 по-прежнему встречается редко. (Примечание: мы считаем сайты, использующие протокол QUIC как использующие HTTP 3, даже если Chrome иногда говорит, что это HTTP 2 + QUIC.) Это данные для корневого документа, для связанных ресурсов значения выглядят немного иначе.

Протокол, используемый для связанных ресурсов
Для связанных ресурсов HTTP 3 используется почти в 100 раз чаще. Как такое может быть? Дело в том, что все сайты ссылаются на одно и то же:

Самые популярные URL ссылок
Есть несколько скриптов, связанных с большой частью веб-сайтов. И это ведь означает, что эти ресурсы будут в кэше, правильно? Увы, больше это не так: с момента выпуска Chrome 86 ресурсы, запрашиваемые с разных доменов, не имеют общего кэша. Firefox планирует реализовать такой же подход. Safari разделяет свой кэш уже многие годы.
Имея такой набор данных веб-страниц и их метрики времени загрузки, было бы здорово узнать о том, из-за чего же тормозят веб-страницы. Мы изучим метрику dominteractive, это время до того момента, как документ становится интерактивным для пользователя. Проще всего рассмотреть корреляцию каждой метрики с dominteractive.

Корреляции метрик с dominteractive
По сути, каждая метрика позитивно коррелирует с dominteractive, за исключением переменной 0–1, обозначающей использование HTTP2 или более старшей версии. Многие из этих метрик также положительно коррелируют друг с другом. Нам нужен более сложный подход, чтобы выйти на отдельные факторы, влияющие на высокий показатель time-to-interactive.
Некоторые из метрик — это тайминги, измеряемые в миллисекундах. Мы можем взглянуть на их диаграмму размаха («ящик с усами»), чтобы понять, на что браузеры тратят своё время.
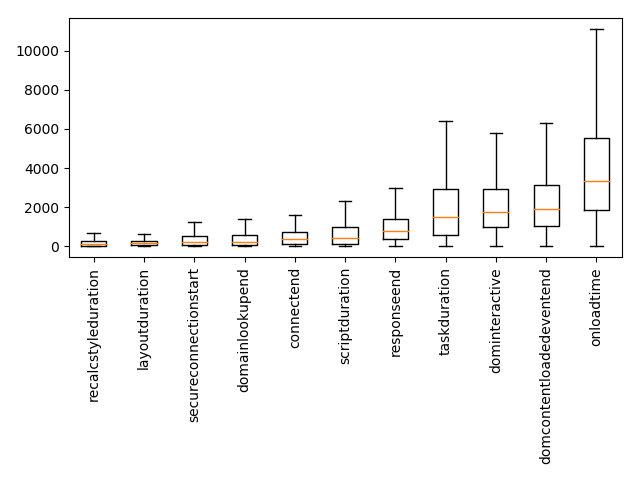
Диаграмма размаха метрик таймингов. Оранжевая линия — это медиана, ящик ограничивает с 25-го по 75-й перцентиль.
Один из способов определения отдельных факторов, влияющих на высокий показатель time-to-interactive — выполнение линейной регрессии, при которой мы прогнозируем dominteractive на основании других метрик. Это означает, что мы назначаем каждой метрике вес и моделируем время dominteractive страницы как взвешенную сумму других метрик, плюс некая константа. Алгоритм оптимизации расставляет веса так, чтобы минимизировать погрешность прогноза для всего набора данных. Величина весов, определённая регрессией, сообщит нам что-то о том, как каждая метрика влияет на медленность страницы.
Из регрессии мы исключим метрики таймингов. Если мы потратим 500 мс на установку соединения, то это добавит 500 мс к dominteractive, но это не особо интересный для нас вывод. По сути, метрики таймингов являются результатами. Мы хотим узнать, что становится их причиной.

Коэффициенты регрессии для метрик, прогнозирующей dominteractive
Числа в скобках — это коэффициенты регрессии, выведенные алгоритмом оптимизации. Можно интерпретировать их как величины в миллисекундах. Хотя к точным значениям нужно относиться скептически (см. примечание ниже), интересно увидеть порядок, назначенный каждому аспекту. Например, модель прогнозирует замедление в 354 мс для каждого перенаправления (редиректа), необходимого для доставки основного документа. Когда основной HTML-документ передаётся по HTTP2 или более высокой версии, модель прогнозирует снижение time-to-interactive на 477 мс. Для каждого запроса, причиной которого стал документ, она прогнозирует добавление 16 мс.
В процессе интерпретации коэффициентов регрессии нужно помнить о том, что мы работаем с упрощённой моделью реальности. На самом деле time-to-interactive не определяется взвешенной суммой этих входящих метрик. Очевидно, что есть причинные факторы, которые модель выявить не может. Бесспорной проблемой являются искажающие факторы. Например, если загрузка основного документа по HTTP2 коррелирует с загрузкой других запросов по HTTP2, то модель встроит это преимущество в веса main_doc_is_http2_or_greater, даже если ускорение вызвано запросами не к основному документу. Нам нужно быть аккуратными, сопоставляя показания модели с выводами о реальном положении дел.
Вот любопытный график dominteractive, разделённый по версиям протокола HTTP, используемым для доставки корневой HTML-страницы.

Диаграмма размаха dominteractive, разделённая по версиям протокола HTTP первого запроса. Оранжевая линия — медиана, ящик ограничивает с 25-го по 75-й перцентиль. Проценты в скобках — доля запросов, выполненная по этому протоколу.
Существует крошечная доля сайтов, до сих пор доставляемых по HTTP 0.9 и 1.0. И эти сайты оказываются быстрыми. Похоже, мы не можем отвязаться от того факта, что протоколы стали быстрее, а поэтому довольные программисты пользуются этим ускорением, доставляя в браузер больше данных.
Это показатели для версии протокола, используемой для доставки корневой HTML-страницы. А если мы рассмотрим влияние протокола, используемого для ресурсов, на которые ссылается этот документ? Если провести регрессию для количества запросов по версии протокола, то получится следующее.

Коэффициенты прогнозирующей dominteractive регрессии для количества запросов по версии протокола
Если бы мы поверили этим показателям, то пришли бы к выводу, что перемещение запрашиваемых ресурсов при переходе с HTTP 1.1 на 2 ускоряется 1,8 раза, а при переходе с HTTP 2 на 3 — замедляется в 0,6 раза. Действительно ли протокол HTTP 3 более медленный? Нет: наиболее вероятное объяснение заключается в том, что HTTP 3 встречается реже, а немногочисленные ресурсы, передаваемые по HTTP 3 (например, Google Analytics), больше среднего влияют на dominteractive.
Давайте спрогнозируем time-to-interactive в зависимости от количества переданных данных при разделении по типам передаваемых данных.

Коэффициенты прогнозирующей dominteractive регрессии для килобайтов, переданных инициатором запроса
Вот похожая регрессия, на этот раз здесь рассматривается количество запросов по типу инициатора запроса.

Коэффициенты прогнозирующей dominteractive регрессии для количества запросов, переданных инициатором запроса
Здесь запросы разделены по инициаторам запросов. Очевидно, что не все запросы равны. Запросы, вызванные элементом компоновки (например, CSS или файлов favicon), и запросы, вызванные CSS (например, шрифтов и других CSS), а также скриптами и iframe значительно замедляют работу. Выполнение запросов по XHR и fetch прогнозируемо выполняются быстрее, чем базовое время dominteractive (вероятно, потому, что эти запросы почти всегда асинхронны). CSS и скрипты часто загружаются так, что препятствуют рендерингу, поэтому неудивительно, что они связаны с замедлением time-to-interactive. Видео относительно малозатратно.
Мы не нашли никаких новых трюков для оптимизации, но анализ даёт нам понимание масштаба влияния, которого следует ожидать от различных оптимизаций. Похоже, чёткое эмпирическое подтверждение имеют следующие утверждения:
- Делайте как можно меньше запросов. Количество запросов важнее, чем количество запрошенных килобайтов.
- По возможности делайте запросы по HTTP2 или более старшей версии протокола.
- Стремитесь по возможности избегать запросов, мешающих рендерингу, старайтесь пользоваться асинхронной загрузкой.
Чтобы разобраться, какие библиотеки используются на странице, мы воспользовались следующим подходом: на каждом сайте мы фиксировали глобальные переменные (например, свойства объекта окна). Далее каждая глобальная переменная, встречавшаяся более шести тысяч раз связывалась (когда это было возможно) с библиотекой JavaScript. Это очень кропотливая работа, но поскольку в наборе данных также содержались запрашиваемые URL для каждой страницы, мы могли изучить пересечение встречаемых переменных и запросов URL, и этого часто было достаточно, чтобы определить, какая библиотека задаёт каждую из глобальных переменных. Глобальные переменные, которые нельзя было с уверенностью связать с какой-то одной библиотекой, игнорировались. Такая методология в определённой мере обеспечивает неполный учёт: библиотеки JS не обязаны оставлять что-то в глобальном пространстве имён. Кроме того, она обладает некоторым шумом, когда разные библиотеки задают одно и то же свойство, и этот факт при привязке библиотек не учитывался.
Какие библиотеки JavaScript используются сегодня наиболее часто? Если следить за темами конференций и постов, было бы вполне логично предположить, что это React, Vue и Angular. Однако в нашем рейтинге они совершенно далеки от вершины.

Просмотреть полный список библиотек по уровню использования
Да, на вершине находится старый добрый jQuery. Первая версия JQuery появилась в 2006 году, то есть 14 человеческих лет назад, но в годах JavaScript это гораздо больше. Если измерять в версиях Angular, то это произошло, вероятно, сотни версий назад. 2006 год был совершенно иным временем. Самым популярным браузером был Internet Explorer 6, крупнейшей социальной сетью — MySpace, а скруглённые углы на веб-страницах были такой революцией, что люди называли их «Веб 2.0». Основная задача JQuery — обеспечение кроссбраузерной совместимости, которая в 2020 году совершенно отличается от ситуации 2006 года. Тем не менее, 14 лет спустя аж половина веб-страниц из нашей выборки загружала jQuery.
Забавно, что 2,2% веб-сайтов выбрасывали ошибку, потому что JQuery не загружался.
Судя по этой десятке лучших, наши браузеры в основном выполняют аналитику, рекламу и код для совместимости со старыми браузерами. Почему-то 8% веб-сайтов определяют полифил setImmediate/clearImmediate для функции, реализация которой даже не планируется ни в одном из браузеров.
Мы снова запустим линейную регрессию, прогнозирующую dominteractive по наличию библиотек. Входящими данными регрессии будет вектор X, где X.length == количество библиотек, где X[i] == 1.0, если библиотека i присутствует, X[i] == 0.0, если её нет. Разумеется, мы знаем, что на самом деле dominteractive не определяется наличием или отсутствием конкретных библиотек. Однако моделирование каждой библиотеки как имеющей вклад в замедление и выполнение регрессии для сотен тысяч примеров всё равно позволяет нам обнаружить интересные находки.

Посмотреть полный список библиотек по коэффициентам регрессии, прогнозирующей dominteractive
Отрицательные коэффициенты означают, что модель прогнозирует меньшее time-to-interactive при наличии этих библиотек, чем при их отсутствии. Разумеется, это не означает, что добавление этих библиотек ускорит ваш сайт, это только значит, что сайты с этими библиотеками оказываются быстрее, чем некая базовая линия, установленная моделью. Результаты могут быть столь же социологическими, сколь и техническими. Например библиотеки для ленивой загрузки по прогнозу обеспечивают снижение time-to-interactive. Возможно, это просто вызвано тем, что страницы с этими библиотеками созданы программистами, потратившими время на оптимизацию с целью быстрой загрузки страниц, поскольку ленивая загрузка приводит непосредственно к этому. Мы не можем отвязать подобные факторы от данной структуры.
Мы можем повторить описанный выше процесс, но на этот раз для прогнозирования onloadtime. Onloadtime — это время, которое требуется для срабатывания события окна «load», то есть время, требуемое для загрузки всех ресурсов страницы. Проведём линейную регрессию точно таким же образом, как и ранее.

Посмотреть полный список библиотек по коэффициентам регрессии, прогнозирующей onloadtime
Это прогноз для размера в мегабайтах кучи, используемой JavaScript.

Посмотреть полный список библиотек по коэффициентам регрессии, прогнозирующей jsheapusedsize
Комментаторы в Интернете с любят высокомерно говорить, что корреляция не равна причинно-следственной связи, и мы в самом деле не можем напрямую вывести из этой модели причинности. При интерпретировании коэффициентов следует быть очень аккуратными, частично это вызвано тем, что может участвовать множество искажающих факторов. Однако этого определённо достаточно для того, чтобы задуматься. Тот факт, что модель связывает замедление time-to-interactive на 982 мс с наличием jQuery, и что половина сайтов загружает этот скрипт, должен навести нас на определённые мысли. Если вы оптимизируете свой сайт, то сверка его списка зависимостей с представленными здесь рейтингами и коэффициентами определённо обеспечит вам приличный показатель того, устранение какой зависимости даст вам наибольший рост производительности.
Так же вам может показаться любопытным наш глубокий анализ о встречаемых при обходе ошибках. Прочитайте нашу статью об ошибках JavaScript в естественных условиях, где мы анализируем найденные ошибки и рассуждаем о том, как они могут нам помочь разрабатывать веб-технологии будущего, менее подверженные ошибкам.
На правах рекламы
VDS для проектов и задач любых масштабов — это про наши эпичные серверы! Новейшие технологии и оборудование, качественный сервис. Поспешите заказать!
