[Перевод] Языковое моделирование с помощью управляемых сверточных сетей
Вступление
Доминирующий на сегодняшний день подход к языковому моделированию основан на рекуррентных нейронных сетях. Их успех в моделировании часто связан со способностью таких сетей обработать неограниченный контекст. В этой статье мы разрабатываем подход для конечного контекста с помощью сложенных (композитных) сверток, которые могут быть более эффективными, поскольку они позволяют распараллеливать последовательные порции данных. Мы предлагаем новый упрощенный нейро-управляемый механизм, который превосходит предложенный Oord et al. (2016b) [26] и исследуем для него влияние ключевых архитектурных решений. Предложенный подход достигает наиболее значимых результатов на бенчмарке WikiText103, даже несмотря на то, что он характерен долгосрочностью зависимостей, а также сопоставимых результатов на бенчмарке Google Billion Words. Наша модель уменьшает задержку при оценивании предложения на порядок, по сравнению с рекуррентными базовыми значениями. Насколько нам известно, это первый случай, когда непериодический подход конкурентоспособен с сильными рекуррентными моделями в подобных крупномасштабных языковых задачах.
-
Введение
Статистические языковые модели оценивают распределение вероятностей последовательности слов путем моделирования вероятности следующего слова с учетом предыдущих слов, т.е.

где wi – отдельные индексы слов в словаре. Языковые модели являются важной частью систем распознавания речи (Yu & Deng, 2014)[34] и машинного перевода (Koehn, 2010) [17].
Недавно было показано, что нейронные сети (Bengio et al., 2003 [1]; Mikolov et al., 2010 [2]; Jozefowicz et al., 2016 [14]) превосходят классические модели языка n-грамм (Kneser & Ney, 1995 [16]; Chen & Goodman, 1996 [3]). Эти классические модели страдают от разреженности данных, что затрудняет представление больших контекстов и, следовательно, анализ долгосрочных зависимостей. Нейронные языковые модели решают эту проблему путем встраивания слов в непрерывное пространство, над которым применяется нейронная сеть. Современное состояние языкового моделирования базируется на сетях долговременной краткосрочной памяти (LSTM; Hochreiter et al., 1997[12]), которые теоретически могут моделировать сколь угодно длинные зависимости.
В этой статье мы вводим новые управляемые сверточные сети и применяем их к языковому моделированию. Сверточные сети могут быть реализованы для представления контекста большого размера и извлечения иерархических характеристик из больших контекстов по более абстрактным функциям (LeCun & Bengio, 1995 [19]). Это позволяет моделировать долгосрочные зависимости, применяя операции сложности

в контексте размером N и шириной ядра k. Напротив, рекуррентные сети рассматривают входные данные как последовательную линейную структуру и поэтому требуют операций порядка

Иерархический анализ входных данных имеет сходство с анализом средствами классических формальных грамматик, построением синтаксических древовидных структур с возрастающей степенью детализации, например, предложения представляются именными и глагольными фразами, каждая из которых включает дополнительную внутреннюю структуру (Manning & Schutze, 1999 [20]; Steedman, 2002 [31]). Иерархическая структура одновременно облегчает обучение, поскольку количество нелинейностей для заданного размера контекста уменьшается по сравнению с линейной структурой, облегчая решение проблемы исчезающего градиента (Glorot & Bengio, 2010 [6]).
Современное техническое обеспечение хорошо адаптируемо к моделям с высокой степенью распараллеливания. В рекуррентных сетях следующий выход зависит от предыдущего скрытого (пока неизвестного) состояния, которое не позволяет распараллеливать элементы последовательности. Однако сверточные сети очень подходят для этой вычислительной парадигмы, поскольку анализ всех входных слов может выполняться одновременно, как будет показано далее (раздел 2).
Было показано, что управление имеет важное значение для достижения рекуррентными нейронными сетями современной производительности (Jozefowicz et al., 2016 [14]). Наши управляемые линейные блоки (GLU) снижают сложность проблемы исчезающего градиента для глубоких архитектур, обеспечивая линейность алгоритма нахождения градиентов при сохранении нелинейных возможностей (раздел 5.2).
Мы показываем, что сверточные сети превосходят и другие, недавно опубликованные, языковые модели, такие как LSTM, обученные в аналогичной обстановке на тесте Google Billion Word Benchmark (Chelba et al., 2013 [2]). Мы также оцениваем способность наших моделей успешно справляться с долгосрочными зависимостями на бенчмарке WikiText-103, для которого модель тестирована на целом абзаце, а не на одном предложении, и достигаем нового уровня знаний на этом наборе данных (Merity et al., 2016 [21]). Наконец, мы показываем, что управляемые линейные единицы (GLU) достигают более высокой точности и сходятся быстрее, чем LSTM-управление Oord et al. (2016 [26]; раздел 4, раздел 5).
2. Подход
В этой статье мы представляем новую модель нейронного языка, которая заменяет повторяющиеся соединения, обычно используемые в рекуррентных сетях, на ограниченные временные свертки. Модели нейронного языка (Bengio et al., 2003 [1]) дают представление
![H = [h_0,. . . , h_N]](https://habrastorage.org/getpro/habr/upload_files/b27/171/209/b271712099a686b5bd272588a5bbb215.svg)
контекста для каждого слова

чтобы можно было предсказать следующее слово

Рекуррентные нейронные сети f вычисляют H с помощью рекуррентной функции

Она по своей сути задает последовательный вычислительный процесс, который нельзя распараллелить по i (вместо этого распараллеливание обычно выполняется над несколькими последовательностями).
Предложенный нами подход свертывает входные данные с помощью функции

и, следовательно, не использует временных зависимостей, поэтому его легче распараллелить по отдельным словам предложения. Этот процесс вычислит каждый контекст как вычислимую функцию от числа предшествующих слов. По сравнению с рекуррентными сетями, размер контекста конечен, но мы продемонстрируем, что бесконечные контексты не являются необходимыми, а наши модели могут представлять достаточно большие контексты и хорошо работать на практике (раздел 5).
Рисунок 1 иллюстрирует архитектуру модели. Слова представлены векторным вложением, хранящимся в таблице поиска

Входом в нашу модель является последовательность слов

которые представлены вложениями слов
![E = [D_{w0},. . . , D_{wN}].](https://habrastorage.org/getpro/habr/upload_files/539/eca/1d3/539eca1d3a11c3bbd3cafa472e93aa44.svg)
Вычисляем скрытые слои

как

где m, n – соответственно, количество входов и выходов характеристических карт, а k – размер патча,

(либо вложения слов, либо выходы предыдущих слоев),


При свертке входных данных мы заботимся о том, чтобы

не содержала информацию о следующих словах. Мы решаем эту проблему путем смещения сверточных входных данных, чтобы ядра не могли видеть будущий контекст (Oord et al., 2016a [25]). В частности, мы обнуляем начало последовательности элементами

предполагая, что первый входной элемент – это начало маркера последовательности, который мы не предсказываем, а


Выходом каждого слоя является линейная проекция

Подобно LSTM, входы умножают каждый элемент матрицы

и контролируют информацию, передаваемую по иерархии. Мы называем этот управляемый механизм закрытыми линейными единицами (GLU). Укладка нескольких слоев поверх ввода E дает представление контекста для каждого слова

Мы обращаем свертку и закрытый линейный блок (GLU) в остаточный блок предварительной активации, который добавляет к выходу вход блока языкового моделирования со управляемыми сверточными сетями (He et al., 2015a [10]). Блокируется узкое место структуры для обеспечения вычислительной эффективности, и каждый блок имеет до 5 уровней (слоев).
Самый простой выбор для получения прогнозной модели – использовать слой softmax, но этот выбор часто вычислительно неэффективен для больших словарей и приближений, таких, как контрастная оценка шума (Gutmann & Hyvarinen [9]) или иерархический softmax (Morin & Bengio, 2005 [24]). Мы выбрали усовершенствование последнего, известное как адаптивный softmax. Оно дает большее значение (большую важность, больший вес) очень частым словам и меньшее – редким словам (Grave et al., 2016a [7]). Это приводит к снижению требований к памяти и к более быстрым вычислениям – как во время обучения, так и во время тестирования.
3. Управляемый механизм
Управляющие механизмы контролируют путь, по которому информация обращается в сети, и доказали свою полезность для рекуррентных нейронных сетей (Hochreiter & Schmidhuber, 1997 [12]). LSTMs обеспечивают долговременную память через отдельную ячейку, управляемую входными и забываемыми (стирающимися) входами. Это позволяет информации беспрепятственно проходить через потенциальное множество временных шагов. Без этого информация могла бы легко исчезнуть при преобразованиях на каждом временном шаге. В отличие от этого, сверточные сети не страдают от подобного исчезающего градиента, и мы экспериментально обнаруживаем, что они не требуют забытых (стирающихся) входных данных.
Поэтому рассматриваем модели, обладающие исключительно выходными вентилями, которые позволяют контролировать в сети, какая информация должна распространяться по иерархии уровней. Мы показываем, что этот механизм может быть полезен для языкового моделирования, поскольку он позволяет модели идентифицировать и использовать слова или функции, имеющие отношение к предсказанию следующего слова. Параллельно с нашей работой Oord et al. (2016b [26]) показали эффективность механизма в стиле LSTM формы

для сверточного моделирования изображений. Позже Kalchbrenner et al. (2016 [15]) расширили этот механизм дополнительными шлюзами для использования при переводе и символьном моделировании языка.
Закрытые линейные блоки (GLU) – это упрощенный механизм управления, основанный на работе Dauphin & Grangier (2015) [35] для недетерминированных входов, которые уменьшают сложность проблемы исчезающего градиента за счет подключения линейных устройств к входам. Это сохраняет нелинейные возможности слоя, позволяя градиенту распространяться через линейный блок без масштабирования. Градиент управления в стиле LSTM, который мы назвали gated tanh unit (GTU), равен
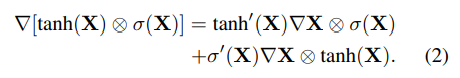
Обращаем внимание, что он постепенно исчезает (по мере того, как мы накладываем слои) из-за коэффициентов уменьшения размера

Напротив, градиент управляемого линейного блока (GLU)

определяет путь

без уменьшения масштаба для активированных управляющих блоков в σ (X). Это можно рассматривать как мультипликативное соединение пропуска, которое помогает градиентам течь через слои. Мы экспериментально сравниваем различные схемы управления в разделе §5.2 и обнаруживаем, что управляемые линейные блоки (GLU) позволяют быстрее сойтись и решить проблему.
4. Эксперименты
4.1 Входящий набор
Мы изложим результаты для двух общедоступных наборов данных при крупномасштабном языковом моделировании. Во-первых, набор данных Google Billion Word (Chelba et al., 2013 [2]) считается одним из крупнейших наборов данных языкового моделирования, с почти миллиардом токенов и словарем, превышающим 800 тыс. слов. В этом наборе данных слова, встречающиеся менее 3 раз, заменяются специальным символом. Данные основаны на английских 30 301 028 предложениях, порядок которых изменен. Во-вторых, WikiText-103 – это меньший набор данных, содержащий более 100 млн. токенов, со словарным запасом около 200 тыс. слов (Merity et al., 2016 [21]). В отличие от GBW, предложения являются последовательными, что позволяет моделям использовать более объемный контекст, а не отдельные предложения. Для обоих наборов данных мы добавляем маркер начала последовательности <S> в начале каждой строки и маркер конца последовательности </S> в конце каждой строки. В корпусе Google Billion Word каждая последовательность представляет собой отдельное предложение, а в WikiText-103 последовательность представляет собой целый абзац. Модель рассматривает <S> и </ S> как входные данные, но предсказывает лишь конец маркера последовательности </S>. Мы оцениваем модели, вычисляя сложность

на представленном стандарте тестовой части каждого набора данных.
4.2 Обучение
Мы реализуем наши модели в Torch (Collobert et al., 2011 [5]) и обучаем на графических процессорах Tesla M40. Большинство наших моделей обучаются на одном графическом процессоре, поскольку мы сосредоточились на определении компактных архитектур с хорошим обобщением и эффективными вычислениями во время тестирования. Мы обучили более крупные модели с настройкой из 8 графических процессоров, скопировав модель на каждый графический процессор и разделив пакет таким образом, чтобы каждый вычислял 1/8 градиента. Затем градиенты суммируются с помощью Nvidia NCCL. Настройка с несколькими графическими процессорами позволила нам обучать модели с более крупными скрытыми блоками.
Мы тренируемся, используя импульс Нестерова (Sutskever et al., 2013 [32]). В то время как стоимость памяти для хранения другого вектора важна для нас, размерность его значительно увеличивает скорость сходимости с минимальными дополнительными вычислениями по сравнению со стандартным стохастическим градиентным спуском. Скорость сходимости была дополнительно увеличена с помощью градиентного отсечения (Pascanu et al., 2013 [27]) и нормализации веса (Salimans & Kingma, 2016 [28]).
![Таблица 1. Архитектуры для моделей. Остаточные строительные блоки показаны в скобках в формате [k, n]. «B» обозначает узкое место архитектуры.](https://habrastorage.org/getpro/habr/upload_files/879/e3c/bf4/879e3cbf49c176fcc35e52d3b84aff1d.PNG "Таблица 1. Архитектуры для моделей. Остаточные строительные блоки показаны в скобках в формате [k, n]. «B» обозначает узкое место архитектуры.")
Паскану и др. (2013) [27] приводят доводы в пользу отсечения градиента, поскольку оно предотвращает проблему скачка градиента, которая характерна для RNN. Однако отсечение градиента не привязано к RNN, поскольку оно может быть получено из общей концепции методов доверительной области. Отсечение градиента обнаруживается с помощью сферической доверительной области

Эмпирически наши эксперименты сходятся значительно быстрее с использованием градиентного отсечения, даже если мы не используем рекуррентную архитектуру. В сочетании, эти методы привели к стабильной и быстрой конвергенции со сравнительно большими скоростями обучения, такими как 1.
4.3 Гиперпараметры
Мы нашли хорошие конфигурации гиперпараметров путем перекрестной проверки со случайным поиском по тестовому набору. Для архитектуры модели мы выбираем количество остаточных блоков между {1,. . . , 10}, размер вложений с {128,. . . , 256}, количество единиц между {128,. . . , 2048}, а ширина ядра – между {3,. . . , 5}. В общем, найти хорошую архитектуру было просто, и эмпирическое правило состоит в том, что чем больше модель, тем лучше производительность. С точки зрения оптимизации, мы инициализируем слоями модели аналогично Каймин (он с соавт., 2015b [11]), их данных с уровнем обучения выборки равномерно в промежутке [1., 2.], для импульса со значением 0,99 и отсечения до 0,1. Хорошие гиперпараметры для оптимизатора довольно просто найти, и оптимальные значения немного изменяются между наборами данных.
5.Результаты
LSTM и рекуррентные сети способны фиксировать долгосрочные зависимости и быстро становятся краеугольным камнем в обработке естественного языка. В этом разделе мы сравниваем сильные модели LSTM и RNN из литературы с нашим управляемым сверточным подходом на двух наборах данных.
Мы находим, что GCNN превосходит сопоставимые результаты LSTM в Google на миллиард слов. Чтобы точно сравнить эти подходы, мы используем одинаковое количество графических процессоров и адаптивную модель вывода softmax (Grave et al., 2016a [7]), поскольку эти переменные оказывают значительное влияние на производительность. В такой настройке GCNN достигает 38,1 тестовой сложности, в то время как сопоставимый LSTM имеет 39,8 сложности (таблица 2).

Кроме того, GCNN обеспечивает высокую производительность при гораздо большей вычислительной эффективности. На рисунке 2 показано, что наш подход закрывает ранее значительный разрыв между моделями, использующими полный softmax и моделями с обычно менее точным иерархическим softmax. Благодаря адаптивному softmax, GCNN требует меньше операций для достижения тех же значений сложности. GCNN превосходит другие современные подходы, за исключением гораздо более объемного LSTM Jozefowicz et al. (2016 [14]), модели, которая требует большего количества графических процессоров и гораздо более затратной с точки зрения вычислений по полному softmax. Для сравнения, самая большая модель, которую мы обучили, достигает 31,9 тестовой сложности по сравнению с 30,6 в этом подходе, но требует обучения только в течение 2 недель на 8 графических процессорах по сравнению с 3 неделями обучения на 32 графических процессорах для LSTM. Обратите внимание, что эти результаты можно улучшить, используя либо экспертный подход (Shazeer et al., 2017 [30]), либо ансамбли этих моделей.
![Рисунок 2. По сравнению с современными решениями (Jozefowicz et al., 2016 [14]), в которых используется полный softmax, адаптивное приближение softmax значительно сокращает количество операций, необходимых для достижения заданной сложности.](https://habrastorage.org/getpro/habr/upload_files/571/bf3/46b/571bf346be581abdec8d1c71eff67e53.PNG "Рисунок 2. По сравнению с современными решениями (Jozefowicz et al., 2016 [14]), в которых используется полный softmax, адаптивное приближение softmax значительно сокращает количество операций, необходимых для достижения заданной сложности.")
Другая важная проблема заключается в том, может ли фиксированный размер контекста GCNN полностью моделировать длинные последовательности. В Google Billion Word средняя длина предложения довольно короткая – всего 20 слов. Мы оцениваем WikiText-103, чтобы определить, может ли модель хорошо работать с набором данных, где доступны гораздо более обширные контексты. В WikiText-103 входная последовательность представляет собой целую статью в Википедии, а не отдельное предложение, что увеличивает среднюю длину до 4000 слов. Однако GCNN также превосходит LSTM по этой проблеме (Таблица 3). Модель GCNN-8 имеет 8 уровней по 800 единиц в каждом, а LSTM – 1024 единиц. Эти результаты показывают, что сети GCNN могут моделировать достаточно большой контекст для достижения очень хороших результатов.

Мы оценили набор данных Gigaword так же как и Chen et al. (2016 [4]) для сравнения с моделями с полным подключением. Обнаружено, что полносвязная и сверточная сети достигают сложности, соответственно, 55,6 и 29,4. Мы также провели предварительные эксперименты с гораздо меньшим набором данных из банка Penn tree. Когда оцениваем предложения независимо друг от друга, GCNN и LSTM имеют сопоставимую тестовую сложность: 108,7 и 109,3 соответственно. Тем не менее, можно добиться лучших результатов, опираясь на предыдущие предложения. В отличие от LSTM, мы обнаружили, что GCNN хорошо подходит для этого небольшого набора данных, и поэтому отмечаем, что модель лучше подходит для задач более крупного масштаба.
5.1 Вычислительная эффективность
Вычислительные затраты важны для языковых моделей. В зависимости от приложения необходимо учитывать ряд показателей. Мы измеряем пропускную способность модели как количество токенов, которые могут быть обработаны в секунду. Пропускную способность можно максимизировать, обрабатывая множество предложений параллельно для амортизации (сглаживания) последовательных операций. Напротив, отзывчивость (чувствительность) – это скорость последовательной обработки ввода, по одному токену за раз. Пропускная способность важна, потому что она указывает время, необходимое для обработки структуры текста, а скорость отклика является индикатором времени, необходимого для завершения обработки предложения. Модель может иметь низкую отзывчивость, но высокую пропускную способность за счет одновременной оценки множества предложений посредством пакетной обработки. В этом случае, такая модель медленно завершает обработку отдельных предложений, но может обрабатывать много предложений с хорошей скоростью.
Мы оцениваем пропускную способность и скорость отклика для моделей, которые достигают примерно значения 43,9 степени сложности в тесте Google Billion Word. Рассматриваем LSTM с 2048 единицами в таблице 2, GCNN-8Bottleneck с 7 блоками Resnet, которые имеют структуру узких мест, как описано в (He et al., 2015a [10]), и GCNN-8 без узких мест. Блок узкого места заклинивает (разделяет) свертку k > 1 между двумя слоями k = 1. Эта конструкция снижает вычислительные затраты за счет уменьшения и увеличения размерности с k = 1 слоями, так что свертка работает в пространстве меньшей размерности. Наши результаты показывают, что использование блоков узких мест важно для поддержания эффективности вычислений.

Пропускная способность LSTM измеряется с помощью большого пакета из 750 последовательностей длиной 20, что дает 15 000 токенов на пакет. Отзывчивость – это средняя скорость обработки последовательности из 15 000 смежных токенов. Таблица 4 показывает, что пропускная способность для LSTM и GCNN одинакова. LSTM очень хорошо работает на графическом процессоре, потому что большой размер пакета в 750 обеспечивает высокую степень распараллеливания для различных предложений. Это связано с тем, что реализация LSTM была тщательно оптимизирована и использует cuDNN, тогда как реализация сверток cuDNN не оптимизирована для одномерных сверток, которые мы используем в нашей модели. Мы считаем, что гораздо лучшая производительность может быть достигнута за счет более эффективной 1-мерной свертки cuDNN. В отличие от LSTM, GCNN можно распараллеливать как по последовательностям, так и по токенам каждой последовательности, что позволяет GCNN иметь в 20 раз более высокую реакцию.
 и Google Billion Word (справа) для моделей с различными механизмами активации. Модели с закрытыми линейными единицами (GLU) сходятся быстрее и с меньшей неопределенностью.")
5.2 Вентильные (управляемые) механизмы
В этом разделе мы сравниваем управляемый линейный блок с другими механизмами, а также с моделями без управления. Мы рассматриваем управляющий механизм (GTU) в стиле LSTM

из (Oord et al., 2016b [17]) и сети, которые используют обычную активацию ReLU или Tanh. Управляющие блоки добавляют параметры, поэтому для релевантного сравнения мы тщательно проверяем модели с сопоставимым количеством параметров. На рисунке 3 (слева) показано, что сети GLU сходятся с меньшими затруднениями, чем другие подходы к WikiText-103. Подобно закрытым линейным модулям, ReLU имеет линейный путь, который позволяет градиентам легко проходить через активные модули. Это приводит к гораздо более быстрой сходимости как для ReLU, так и для GLU. С другой стороны, ни Tanh, ни GTU не имеют этого линейного пути и, следовательно, страдают от проблемы исчезающего градиента. В GTU как входы, так и управляющие устройства могут сокращать градиент, когда устройства насыщаются.
Сравнение моделей GTU и Tanh позволяет нам измерить эффект управления, поскольку модель Tanh можно рассматривать как сеть GTU с удаленными сигмоидальными модулями управления. Результаты (Рисунок 3, слева) показывают, что управляющие блоки имеют большое значение и предоставляют полезные возможности моделирования, поскольку существует большая разница в производительности между блоками GTU и Tanh. Аналогично, хотя блок ReLU не является копией блоков управления в GLU, его можно рассматривать как упрощение

, где входы становятся активными в зависимости от знака ввода. Также в этом случае блоки GLU снижают неоднозначность.
На рисунке 3 (справа) мы иллюстрируем повторение того же эксперимента с большим набором данных Google Billion Words. Мы рассматриваем ограниченный бюджет времени в 100 часов из-за значительного времени обучения, необходимого для этой задачи. Подобно WikiText-103, управляемые линейные блоки достигают лучших результатов в этой проблеме. Существует разрыв примерно в 5 пунктов между GLU и ReLU, что похоже на разницу между моделями LSTM и RNN, измеренными (Jozefowicz et al., 2016 [14]) на одном и том же наборе данных.
5.3 Нелинейное моделирование
К настоящему времени эксперименты показали, что управляемый линейный блок выигрывает от линейного пути, который обеспечивает блок, по сравнению с другими нелинейностями. Затем мы сравниваем сети с GLU с чисто линейными сетями и сетями с билинейными слоями, чтобы измерить влияние нелинейного пути, обеспечиваемого входами GLU. Одним из мотивов этого эксперимента является успех линейных моделей во многих задачах обработки естественного языка (Manning & Schutze, 1999 [20]). Мы рассматриваем глубокие линейные сверточные сети, в которых слои лишены управляемых устройств GLU и имеют вид

Наложение нескольких слоев друг на друга – это просто факторизация модели, которая остается линейной до softmax, после чего она становится лог-линейной. Другой вариант GLU – это билинейные слои (Mnih & Hinton, 2007 [23]), которые имеют форму

 и Wiki-103 (справа). Мы наблюдаем, что модели с большим контекстом достигают лучших результатов, но результаты начинают быстро уменьшаться после контекста 20.")
На рисунке 5 показано, что лучше всего работают GLU, за ними следуют билинейные слои, а затем линейные слои. Билинейные слои улучшаются по сравнению с линейными более чем на 40 точек затруднения, а GLU улучшает еще 20 точек затруднений по сравнению с билинейной моделью. Линейная модель работает очень плохо (115) даже по сравнению с 67,6 языка 5-грамм модели Кнезера-Нея, хотя первая имеет доступ к большему контексту. Удивительно, но введения билинейных единиц достаточно, чтобы достичь 61 недоумения в Google Billion Word, что превосходит как языка 5-грамм модели Кнезера-Нея, так и нелинейную нейронную модель (Ji et al., 2015 [13]).
5.4 Размер контекста

На рисунке 4 показано влияние размера контекста на управляемую CNN. Мы пробовали разные комбинации глубины сети и ширины ядра для каждого размера контекста и выбрали наиболее эффективную для каждого размера. Как правило, более крупные контексты повышают точность, но возвращаемые результаты резко уменьшаются с окнами прогноза, превышающими 40 слов, даже для WikiText-103, где мы можем использовать всю статью в Википедии. Это означает, что неограниченный контекст, предлагаемый повторяющимися моделями, не является строго необходимым для языкового моделирования. Кроме того, этот результат также согласуется с тем фактом, что хорошая производительность с рекуррентными сетями может быть получена путем усечения градиентов только после 40 временных шагов с использованием усеченного обратного распространения во времени. На рисунке 4 также показано, что WikiText-103 намного больше выигрывает от более широкого контекста, чем Google Billion Word, поскольку производительность ухудшается резко с меньшими контекстами. WikiText-103 предоставляет гораздо больше контекста, чем Google Billion Word, где средний размер предложения равен 20. Однако, хотя средний размер документов близок к 4000 токенов, обнаружено, что высокая производительность может быть достигнута при размере контекста всего 30 токенов.
5.5 Обучение
В этом разделе мы проводим исследование воздействия нормализации веса и ограничения градиента. Отдельно проверяем гиперпараметры каждой конфигурации, чтобы сравнение было справедливым. Из-за дороговизны реализации каждого из этих экспериментов мы рассматриваем только одну итерацию по обучающим данным. На рисунке 6 показано, что оба метода значительно ускоряют сходимость. В частности, нормализация веса увеличивает скорость более чем в два раза. Это ускорение частично связано с возможностью использовать гораздо более высокие скорости обучения (1 вместо 0,01), чем это возможно было бы в противном случае. Как отсечение, так и нормализация веса добавляют вычислительные затраты, но незначительно, по сравнению с большим выигрышем в скорости сходимости.

6. Заключение
Мы вводим сверточную нейронную сеть для языкового моделирования с новым управляемым механизмом. По сравнению с рекуррентными нейронными сетями, наш подход строит иерархическое представление входных слов, что облегчает использование долгосрочных зависимостей, сходных по духу с древовидным анализом формализмов (фреймов) лингвистической грамматики. Это же свойство облегчает обучение, поскольку объекты передаются через фиксированное число слоев и нелинейностей, в отличие от рекуррентных сетей, где количество шагов обработки различается в зависимости от положения слова во входных данных. Результаты показывают, что наша управляемая сверточная сеть достигает нового уровня техники на WikiText-103. На тесте Google Billion Word мы показываем, что конкурентные результаты могут быть достигнуты при значительно меньшем количестве ресурсов.
Ссылки
Spoiler
-
Bengio, Yoshua, Ducharme, Rejean, Vincent, Pascal, and Jauvin, Christian. A neural probabilistic language model. journal of machine learning research, 3(Feb):1137–1155, 2003.
-
Chelba, Ciprian, Mikolov, Tomas, Schuster, Mike, Ge, Qi, Brants, Thorsten, Koehn, Phillipp, and Robinson, Tony. One billion word benchmark for measuring progress in statistical language modeling. arXiv preprint arXiv:1312.3005, 2013.
-
Chen, Stanley F and Goodman, Joshua. An empirical study of smoothing techniques for language modeling. In Proceedings of the 34th annual meeting on Association for Computational Linguistics, pp. 310–318. Association for Computational Linguistics, 1996.
-
Chen, Wenlin, Grangier, David, and Auli, Michael. Strategies for training large vocabulary neural language models. CoRR, abs/1512.04906, 2016.
-
Collobert, Ronan, Kavukcuoglu, Koray, and Farabet, Clement. Torch7: A Matlab-like Environment for Machine Learning. In BigLearn, NIPS Workshop, 2011. URL http://torch.ch.
-
Glorot, Xavier and Bengio, Yoshua. Understanding the difficulty of training deep feedforward neural networks. The handbook of brain theory and neural networks, 2010.
-
Grave, E., Joulin, A., Cisse, M., Grangier, D., and Jegou, H. Efficient softmax approximation for GPUs. ArXiv e-prints, September 2016a.
-
Grave, E., Joulin, A., and Usunier, N. Improving Neural Language Models with a Continuous Cache. ArXiv e-prints, December 2016b.
-
Gutmann, Michael and Hyvarinen, Aapo. Noise-contrastive estimation: A new estimation principle for unnormalized statistical models.
-
He, Kaiming, Zhang, Xiangyu, Ren, Shaoqing, and Sun, Jian. Deep residual learning for image recognition. arXiv preprint arXiv:1512.03385, 2015a.
-
He, Kaiming, Zhang, Xiangyu, Ren, Shaoqing, and Sun, Jian. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, pp. 1026–1034, 2015b.
-
Hochreiter, Sepp and Schmidhuber, Jurgen. Long short-term memory. Neural computation, 9(8):1735–1780, 1997.
-
Ji, Shihao, Vishwanathan, SVN, Satish, Nadathur, Anderson, Michael J, and Dubey, Pradeep. Blackout: Speeding up recurrent neural network language models with very large vocabularies. arXiv preprint arXiv:1511.06909, 2015.
-
Jozefowicz, Rafal, Vinyals, Oriol, Schuster, Mike, Shazeer, Noam, and Wu, Yonghui. Exploring the limits of language modeling. arXiv preprint arXiv:1602.02410, 2016.
-
Kalchbrenner, Nal, Espeholt, Lasse, Simonyan, Karen, van den Oord, Aaron, Graves, Alex, and Kavukcuoglu, Koray. Neural Machine Translation in Linear Time. arXiv, 2016.
-
Kneser, Reinhard and Ney, Hermann. Improved backing-off for m-gram language modeling. In Acoustics, Speech, and Signal Processing, 1995. ICASSP-95., 1995 International Conference on, volume 1, pp. 181–184. IEEE, 1995.
-
Koehn, Philipp. Statistical Machine Translation. Cambridge University Press, New York, NY, USA, 1st edition, 2010. ISBN 0521874157, 9780521874151.
-
Kuchaiev, Oleksii and Ginsburg, Boris. Factorization tricks for LSTM networks. CoRR, abs/1703.10722, 2017. URL http://arxiv.org/abs/1703.10722.
-
LeCun, Yann and Bengio, Yoshua. Convolutional networks for images, speech, and time series. The handbook of brain theory and neural networks, 3361(10):1995, 1995.
-
Manning, Christopher D and Schutze, Hinrich. Foundations of statistical natural language processing, 1999.
-
Merity, S., Xiong, C., Bradbury, J., and Socher, R. Pointer Sentinel Mixture Models. ArXiv e-prints, September 2016.
-
Mikolov, Toma´s, Martin, Karafiat, Burget, Lukas, Cernocky, Jan, and Khudanpur, Sanjeev. Recurrent Neural Network based Language Model. In Proc. of INTERSPEECH, pp. 1045–1048
-
Mnih, Andriy and Hinton, Geoffrey. Three new graphical models for statistical language modelling. In Proceedings of the 24th international conference on Machine learning, pp. 641–648. ACM, 2007.
-
Morin, Frederic and Bengio, Yoshua. Hierarchical probabilistic neural network language model. In Aistats, volume 5, pp. 246–252. Citeseer, 2005.
-
Oord, Aaron van den, Kalchbrenner, Nal, and Kavukcuoglu, Koray. Pixel recurrent neural networks. arXiv preprint arXiv:1601.06759, 2016a.
-
Oord, Aaron van den, Kalchbrenner, Nal, Vinyals, Oriol, Espeholt, Lasse, Graves, Alex, and Kavukcuoglu, Koray. Conditional image generation with pixelcnn decoders. arXiv preprint arXiv:1606.05328, 2016b.
-
Pascanu, Razvan, Mikolov, Tomas, and Bengio, Yoshua. On the difficulty of training recurrent neural networks. In Proceedings of The 30th International Conference on Machine Learning, pp. 1310–1318, 2013.
-
Salimans, Tim and Kingma, Diederik P. Weight normalization: A simple reparameterization to accelerate training of deep neural networks. arXiv preprint arXiv:1602.07868, 2016.
-
Shazeer, Noam, Pelemans, Joris, and Chelba, Ciprian. Skip-gram language modeling using sparse non-negative matrix probability estimation. arXiv preprint arXiv:1412.1454, 2014.
-
Shazeer, Noam, Mirhoseini, Azalia, Maziarz, Krzysztof, Davis, Andy, Le, Quoc V., Hinton, Geoffrey E., and Dean, Jeff. Outrageously large neural networks: The sparsely-gated mixtureof-experts layer. CoRR, abs/1701.06538, 2017. URL http://arxiv.org/abs/1701.06538.
-
Steedman, Mark. The syntactic process. 2002.
-
Sutskever, Ilya, Martens, James, Dahl, George E, and Hinton, Geoffrey E. On the importance of initialization and momentum in deep learning. 2013.
-
Wang, Mingxuan, Lu, Zhengdong, Li, Hang, Jiang, Wenbin, and Liu, Qun. gencnn: A convolutional architecture for word sequence prediction. CoRR, abs/1503.05034, 2015. URL http://arxiv.org/abs/1503.05034.
-
Yu, Dong and Deng, Li. Automatic Speech Recognition: A Deep Learning Approach. Springer Publishing Company, Incorporated, 2014. ISBN 1447157788, 9781447157786.
-
Dauphin, Yann N and Grangier, David. Predicting distributions with linearizing belief networks. arXiv preprint arXiv:1511.05622, 2015.