Профилирование в облаке и не только
Приложение, оптимально использующее вычислительные ресурсы, это всегда хорошо и приятно. А если такое приложение работает в облаке, то ещё и выгодно. Порой очень выгодно. Просто потому, что в один квант оплаченного облачного вычислительного ресурса влезает, например, больше показанных в браузере котиков вместе с рекламой или платёжных транзакций за подписки на тех же котиков. И если с профилированием Go приложений всё более или менее понятно, то для приложений, написанных на C или C++, всё гораздо интереснее.
Так как большинство проблем с производительностью материализуются, как правило, в продакшене, то нас будут интересовать те инструменты, которые не требуют инструментализации кода и, следовательно, остановки и перезапуска рабочих процессов. Кроме того, я не буду упоминать профилировщики, которые анализируют работу кода на уровне микроархитектуры процессора типа vTune. Во-первых, на эту тему статей и так хватает. Во-вторых, я ошибочно полагаю, что вопросы микроархитектуры больше актуальны для разработчиков middleware типа серверов баз данных или библиотек, которые настолько круты, что Хабр не читают. Итак.
До недавнего времени одним из таких инструментов были Google perftools. Они включают два профилировщика: для CPU и для оперативной памяти. Начнём с первого.
Чтобы ваша программа стала профилируемой, её необходимо слинковать вместе с профилировщиком. Можно статически, можно динамически или же вообще подгрузить при помощи LD_PRELOAD. Его размер составляет около 60k, и он более никак не нагружает систему, когда не используется. Так что всегда линковаться с ним на боевых серверах будет не слишком накладно. Активируется он установкой переменной окружения CPUPROFILE:
$ CPUPROFILE=/tmp/envoy.prof envoy --concurrency 1 -c /path/to/config.yamlВ этом случае статистика начинает собираться с момента запуска исполняемого файла. Если дополнительно установить CPUPROFILESIGNAL=12, то активация будет включаться и выключаться по пользовательскому сигналу 12 (SIGUSR2).
Принцип работы CPU-профилировщика заключается в том, что он периодически (период тоже можно изменить) делает снимок текущих стеков процесса и сохраняет их файл, который можно проанализировать утилитой pprof. Например, чтобы быстро оценить, какие функции больше других — или, точнее сказать, чаще других — нагружают процессор, достаточно ввести
$ pprof -text /tmp/envoy.prof
File: envoy-static
Type: cpu
Showing nodes accounting for 17.74s, 86.75% of 20.45s total
Dropped 900 nodes (cum <= 0.10s)
flat flat% sum% cum cum%
5.19s 25.38% 25.38% 17.02s 83.23% deflate_fast
4.04s 19.76% 45.13% 4.04s 19.76% longest_match
3.92s 19.17% 64.30% 3.92s 19.17% compress_block
3.04s 14.87% 79.17% 3.04s 14.87% slide_hash
0.62s 3.03% 82.20% 0.63s 3.08% crc32_z
0.18s 0.88% 83.08% 0.18s 0.88% writev
0.12s 0.59% 83.67% 0.12s 0.59% readv
0.11s 0.54% 84.21% 0.11s 0.54% close
0.08s 0.39% 84.60% 0.17s 0.83% std::__uniq_ptr_impl::_M_ptr
0.06s 0.29% 84.89% 0.16s 0.78% std::get
0.06s 0.29% 85.18% 0.18s 0.88% std::unique_ptr::get
0.04s 0.2% 85.38% 18.54s 90.66% http_parser_execute
0.03s 0.15% 85.53% 0.33s 1.61% Envoy::Router::Filter::decodeHeaders
0.03s 0.15% 85.67% 0.26s 1.27% absl::container_internal::raw_hash_set::find
0.02s 0.098% 85.77% 17.16s 83.91% Envoy::Http::Http1::ClientConnectionImpl::onBody
0.01s 0.049% 85.82% 0.12s 0.59% Envoy::Event::DispatcherImpl::clearDeferredDeleteList
0.01s 0.049% 85.87% 20.03s 97.95% Envoy::Event::FileEventImpl::mergeInjectedEventsAndRunCb
0.01s 0.049% 85.92% 17.06s 83.42% Envoy::Extensions::Compression::Gzip::Compressor::ZlibCompressorImpl::process
0.01s 0.049% 85.97% 0.13s 0.64% Envoy::Http::ConnectionManagerImpl::ActiveStream::encodeData
0.01s 0.049% 86.01% 0.11s 0.54% Envoy::Http::HeaderString::HeaderString
0.01s 0.049% 86.06% 0.32s 1.56% Envoy::Http::Http1::ClientConnectionImpl::onHeadersComplete
0.01s 0.049% 86.11% 17.18s 84.01% Envoy::Http::Http1::ConnectionImpl::dispatchBufferedBody
0.01s 0.049% 86.16% 19.14s 93.59% Envoy::Network::ConnectionImpl::onReadReady
0.01s 0.049% 86.21% 0.24s 1.17% Envoy::Network::ConnectionImpl::onWriteReady
0.01s 0.049% 86.26% 0.20s 0.98% Envoy::Network::IoSocketHandleImpl::read
0.01s 0.049% 86.31% 0.21s 1.03% Envoy::Network::RawBufferSocket::doRead
...Для более детального анализа можно воспользоваться довольно удобным web-интерфейсом, который предоставляет тот же pprof:
$ pprof -http=localhost:8080 /tmp/envoy.profТеперь по адресу http://localhost:8080 можно взглянуть на красивый граф вызовов функции (callgraph)
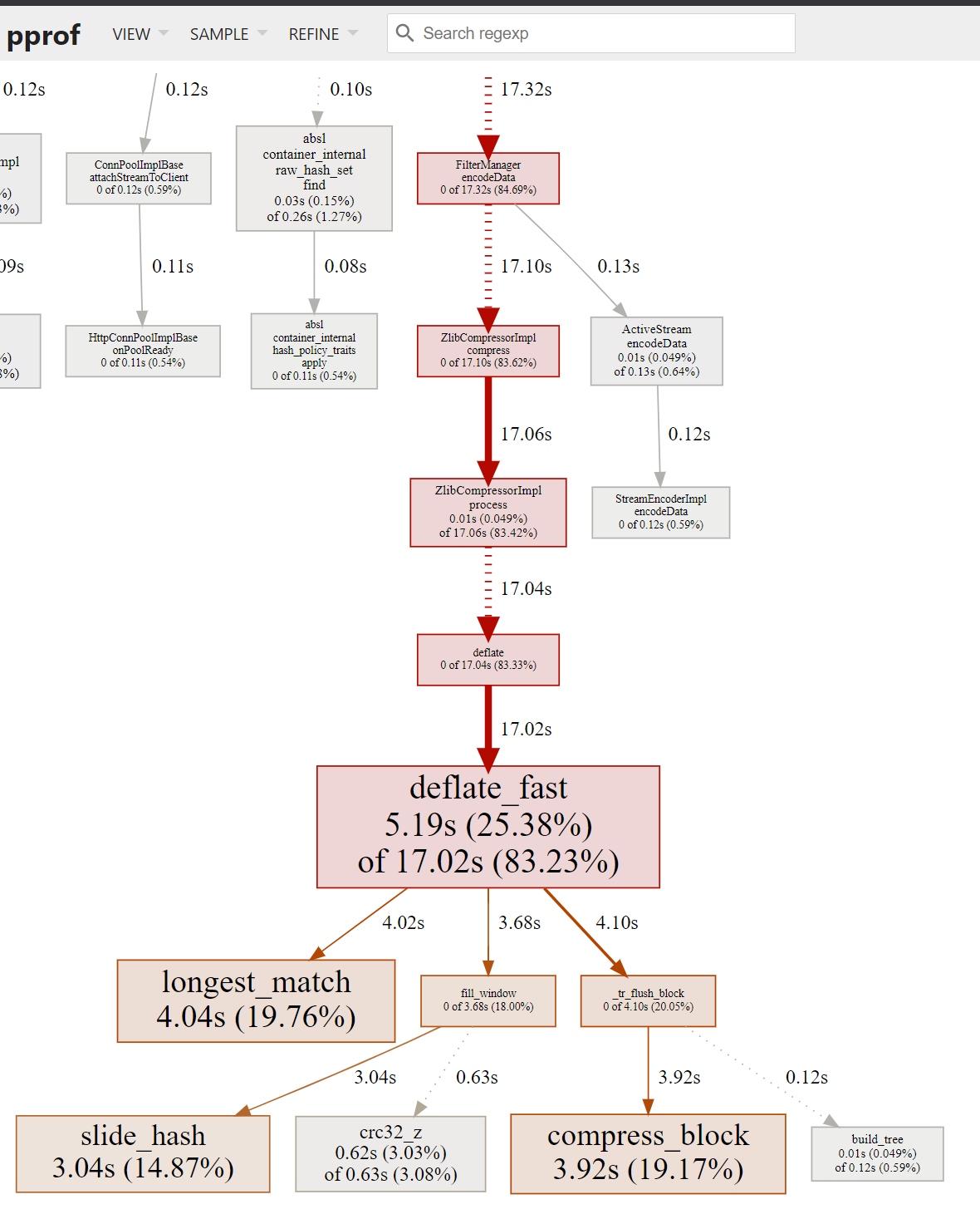
и на flamegraph
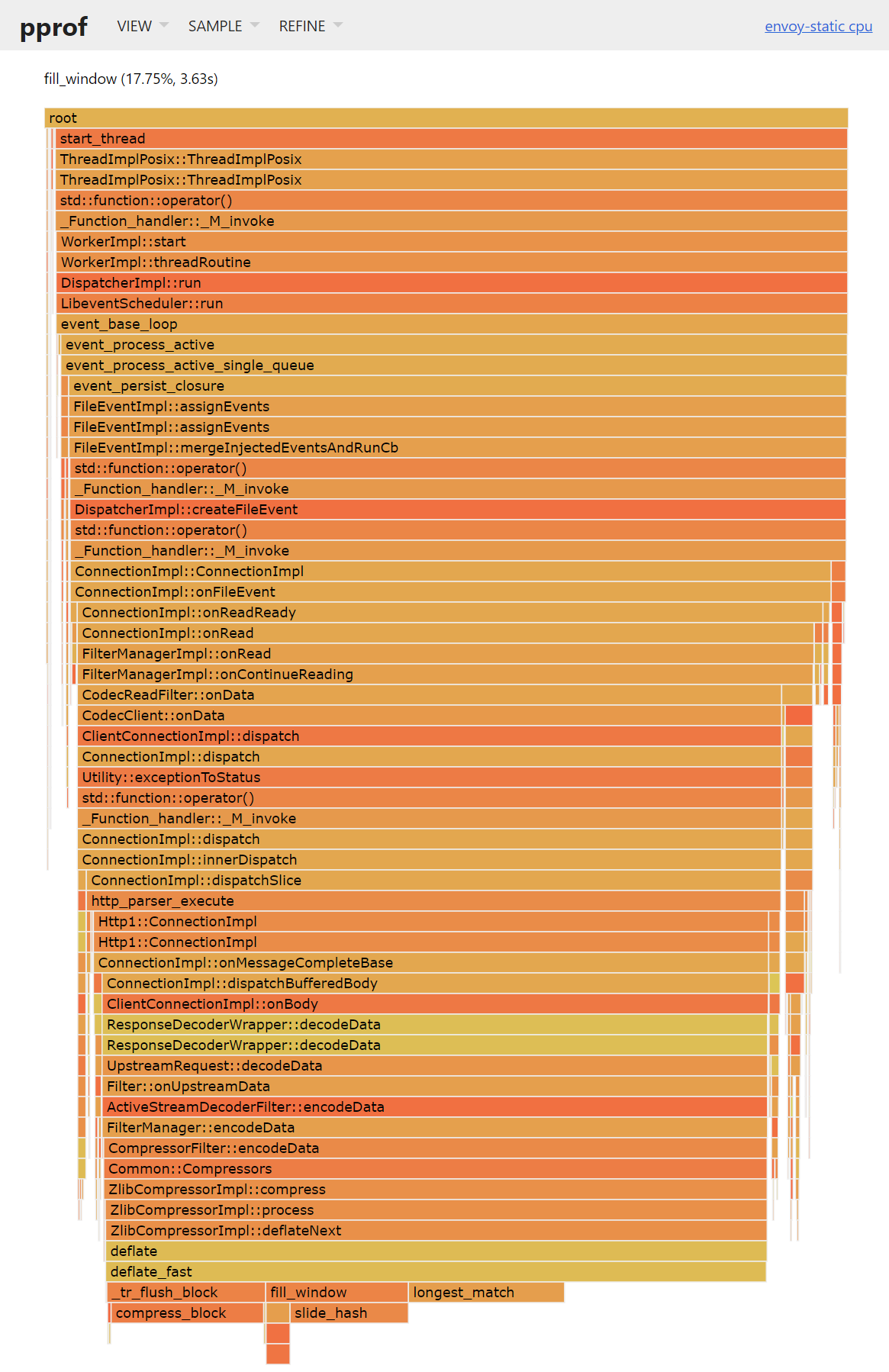
С анализом же расхода памяти всё несколько сложнее, покуда профилировщик кучи является органической частью tcmalloc (thread caching malloc) — альтернативного менеджера памяти от gperftools минимизирующего количество системных вызовов за счет предварительного выделения памяти сверх необходимого. То есть, чтобы иметь возможность профилировать память на боевой системе, необходимо отказаться от стандартных реализаций malloc() и new и всегда линковаться с tcmalloc. И хоть tcmalloc считается быстрее и эффективнее особенно в многопоточных программах, не все готовы его использовать хотя бы из-за немного большего расхода памяти. Тем не менее профилировать память с ним так же просто как и CPU:
$ HEAPPROFILE=/tmp/envoyhprof envoy --concurrency 1 -c /path/to/config.yaml
…
Dumping heap profile to /tmp/envoyhprof.0001.heap (1024 MB allocated cumulatively, 6 MB currently in use)
Dumping heap profile to /tmp/envoyhprof.0002.heap (2048 MB allocated cumulatively, 6 MB currently in use)
Dumping heap profile to /tmp/envoyhprof.0003.heap (3072 MB allocated cumulatively, 6 MB currently in use)
Dumping heap profile to /tmp/envoyhprof.0004.heap (4096 MB allocated cumulatively, 6 MB currently in use)
Dumping heap profile to /tmp/envoyhprof.0005.heap (5120 MB allocated cumulatively, 6 MB currently in use)
^C
Dumping heap profile to /tmp/envoyhprof.0006.heap (Exiting, 5 MB in use)Теперь, чтобы узнать какие функции больше всего выделяли память на куче, надо снова воспользоваться pprof:
$ pprof -text -sample_index=alloc_space /tmp/envoyhprof.0005.heap
File: envoy-static
Type: alloc_space
Showing nodes accounting for 1558.99MB, 98.71% of 1579.32MB total
Dropped 1117 nodes (cum <= 7.90MB)
flat flat% sum% cum cum%
1043.23MB 66.06% 66.06% 1043.23MB 66.06% zcalloc
240.73MB 15.24% 81.30% 240.73MB 15.24% Envoy::Zlib::Base::Base
150.71MB 9.54% 90.84% 406.68MB 25.75% std::make_unique
79.15MB 5.01% 95.85% 79.15MB 5.01% std::allocator_traits::allocate
18.68MB 1.18% 97.04% 26.62MB 1.69% Envoy::Http::ConnectionManagerImpl::newStream
15.18MB 0.96% 98.00% 15.18MB 0.96% Envoy::InlineStorage::operator new
8.39MB 0.53% 98.53% 8.39MB 0.53% std::__cxx11::basic_string::basic_string
1.98MB 0.13% 98.65% 31.99MB 2.03% Envoy::Http::Http1::allocateConnPool(Envoy::Event::Dispatcher&, Envoy::Random::RandomGenerator&, std::shared_ptr, Envoy::Upstream::ResourcePriority, std::shared_ptr const&, std::shared_ptr const&, Envoy::Upstream::ClusterConnectivityState&)::$_1::operator()
0.93MB 0.059% 98.71% 38.29MB 2.42% Envoy::Server::ConnectionHandlerImpl::ActiveTcpListener::newConnection
0 0% 98.71% 59.54MB 3.77% Envoy::Buffer::WatermarkBufferFactory::create
0 0% 98.71% 73.55MB 4.66% Envoy::ConnectionPool::ConnPoolImplBase::newStream
...Как следует из таблицы, больше всего памяти выделяла zcalloc() из zlib, что совсем не удивительно, поскольку во время профилирования приложение сжимало прокачиваемый через себя трафик.
Впрочем, это не самая интересная метрика. Обычно для нас важнее функции, которые используют больше всего памяти в настоящий момент:
$ pprof -text -sample_index=inuse_space /tmp/envoyhprof.0005.heap
File: envoy-static
Type: inuse_space
Showing nodes accounting for 6199.96kB, 96.84% of 6402.51kB total
Dropped 1016 nodes (cum <= 32.01kB)
flat flat% sum% cum cum%
2237.76kB 34.95% 34.95% 3232.51kB 50.49% std::make_unique
2041.45kB 31.89% 66.84% 2041.45kB 31.89% std::allocator_traits::allocate
375.03kB 5.86% 72.69% 753.26kB 11.77% google::protobuf::DescriptorPool::Tables::AllocateString[abi:cxx11]
267.78kB 4.18% 76.88% 267.78kB 4.18% std::__cxx11::basic_string::_M_mutate
201.61kB 3.15% 80.03% 201.61kB 3.15% zalloc_with_calloc
160.43kB 2.51% 82.53% 160.43kB 2.51% google::protobuf::Arena::CreateMessageInternal (inline)
146.74kB 2.29% 84.82% 146.74kB 2.29% std::__cxx11::basic_string::_M_construct
141.38kB 2.21% 87.03% 157.38kB 2.46% google::protobuf::DescriptorPool::Tables::AllocateMessage
139.88kB 2.18% 89.22% 139.88kB 2.18% google::protobuf::DescriptorPool::Tables::AllocateEmptyString[abi:cxx11]
88.04kB 1.38% 90.59% 113.12kB 1.77% google::protobuf::DescriptorPool::Tables::AllocateFileTables
72.52kB 1.13% 91.72% 72.90kB 1.14% ares_init_options
71kB 1.11% 92.83% 71kB 1.11% _GLOBAL__sub_I_eh_alloc.cc
69.81kB 1.09% 93.92% 69.81kB 1.09% zcalloc
51.16kB 0.8% 94.72% 51.16kB 0.8% google::protobuf::Arena::CreateArray (inline)
46.81kB 0.73% 95.45% 60.41kB 0.94% google::protobuf::Arena::CreateInternal (inline)
37.23kB 0.58% 96.03% 37.23kB 0.58% re2::PODArray::PODArray
33.53kB 0.52% 96.56% 33.53kB 0.52% std::__cxx11::basic_string::_M_assign
11.50kB 0.18% 96.74% 2213.77kB 34.58% Envoy::ConstSingleton::get
6.06kB 0.095% 96.83% 38.85kB 0.61% google::protobuf::internal::ArenaStringPtr::Set
0.24kB 0.0038% 96.84% 2590.71kB 40.46% Envoy::Server::InstanceImpl::InstanceImpl
0 0% 96.84% 79.56kB 1.24% Envoy::(anonymous namespace)::jsonConvertInternal
0 0% 96.84% 84.48kB 1.32% Envoy::(anonymous namespace)::tryWithApiBoosting
0 0% 96.84% 726.42kB 11.35% Envoy::Config::ApiTypeOracle::getEarlierVersionDescriptor
0 0% 96.84% 77.22kB 1.21% Envoy::Config::Utility::createTagProducer
0 0% 96.84% 706.72kB 11.04% Envoy::Config::Utility::getAndCheckFactory
0 0% 96.84% 707.38kB 11.05% Envoy::Config::Utility::getFactoryByType
...Ожидаемо, большую часть памяти держит std::make_unique(). И вообще внутри кода Envoy оптимизировать особо нечего — главные потребители находятся в сторонних библиотеках. Однако если взглянуть на callgraph или flamegraph, то можно узнать, например, на какие функции обратить внимание, чтобы пореже звать std::make_unique(). Web-интерфейс в этом случае наиболее удобен
$ pprof -http=localhost:8080 /tmp/envoyhprof.0005.heapВ браузере вы увидите что-то вроде
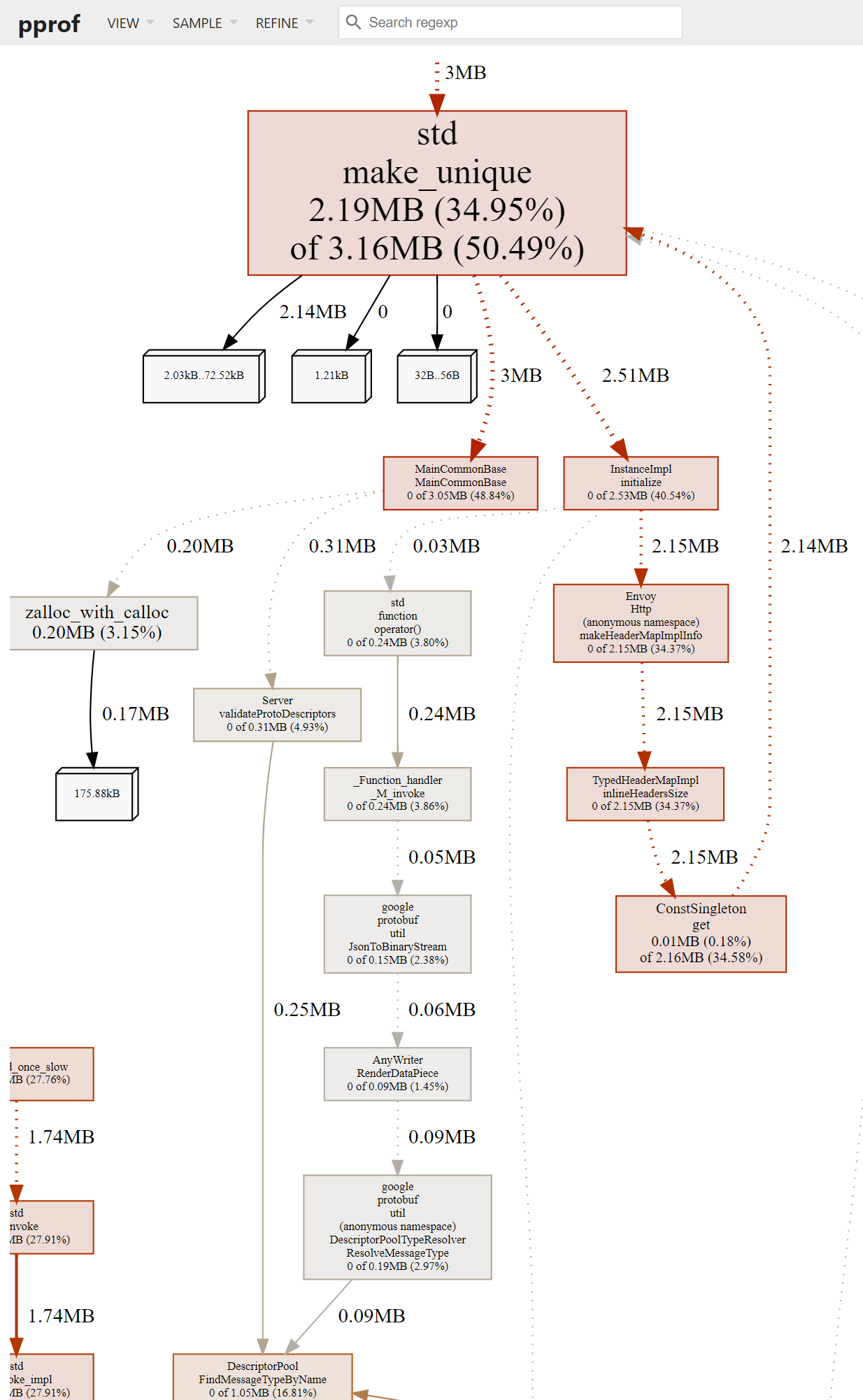
и
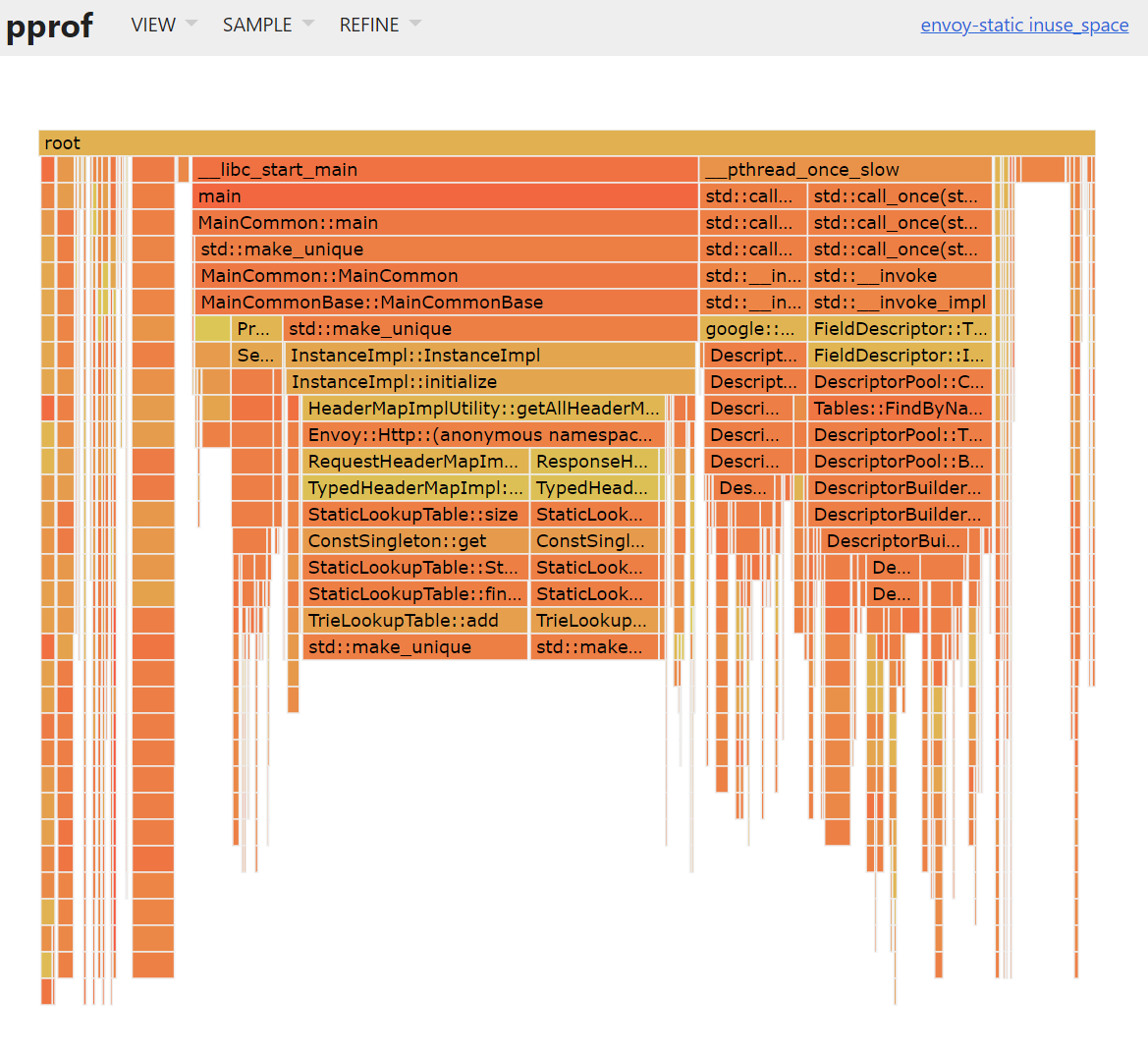
Можно также проверить, не течет ли память. Вычтем из результата самую первую часть дампа, где происходит инициализация программы:
$ pprof -text -sample_index=inuse_space --base=/tmp/envoyhprof.0001.heap /tmp/envoyhprof.0005.heap
File: envoy-static
Type: inuse_space
Showing nodes accounting for 1460B, 10.38% of 14060B total
flat flat% sum% cum cum%
1460B 10.38% 10.38% 1460B 10.38% hist_accumulate
0 0% 10.38% 1460B 10.38% Envoy::Event::DispatcherImpl::DispatcherImpl(std::__cxx11::basic_string const&, Envoy::Api::Api&, Envoy::Event::TimeSystem&, std::shared_ptr const&)::$_1::operator()
0 0% 10.38% 1460B 10.38% Envoy::Event::DispatcherImpl::run
0 0% 10.38% 1460B 10.38% Envoy::Event::DispatcherImpl::runPostCallbacks
0 0% 10.38% 1460B 10.38% Envoy::Event::LibeventScheduler::run
0 0% 10.38% 1460B 10.38% Envoy::Event::SchedulableCallbackImpl::SchedulableCallbackImpl(Envoy::CSmartPtr&, std::function)::$_0::__invoke
0 0% 10.38% 1460B 10.38% Envoy::Event::SchedulableCallbackImpl::SchedulableCallbackImpl(Envoy::CSmartPtr&, std::function)::$_0::operator()
0 0% 10.38% 1460B 10.38% Envoy::MainCommon::main
0 0% 10.38% 1460B 10.38% Envoy::MainCommon::run
0 0% 10.38% 1460B 10.38% Envoy::MainCommonBase::run
0 0% 10.38% 1460B 10.38% Envoy::Server::InstanceImpl::run
0 0% 10.38% 1460B 10.38% Envoy::Stats::ParentHistogramImpl::merge
0 0% 10.38% 730B 5.19% Envoy::Stats::ThreadLocalHistogramImpl::merge
0 0% 10.38% 1460B 10.38% Envoy::Stats::ThreadLocalStoreImpl::mergeHistograms(std::function)::$_2::operator()
0 0% 10.38% 1460B 10.38% Envoy::Stats::ThreadLocalStoreImpl::mergeInternal
0 0% 10.38% 1460B 10.38% __libc_start_main
0 0% 10.38% 1460B 10.38% event_base_loop
0 0% 10.38% 1460B 10.38% event_process_active
0 0% 10.38% 1460B 10.38% event_process_active_single_queue
0 0% 10.38% 1460B 10.38% main
0 0% 10.38% 1460B 10.38% std::_Function_handler::_M_invoke
0 0% 10.38% 1460B 10.38% std::function::operator()Всё выглядит неплохо, память весьма умеренно тратится только на хранение накопленной статистики.
По закону жанра на этом месте должны начаться проблемы. Заключаются они в том, что не так давно Google выложил в своём аккаунте на GitHub новый, улучшенный tcmalloc. В котором, кэши памяти создаются не для потоков, как в оригинальной версии, а для ядер процессора. В задачах, создающих большое количество потоков, это может заметно улучшить производительность и снизить расход памяти.
Плохая же новость в том, что в новом tcmalloc отсутствует профилировщик. Однако же он теперь не особенно-то и нужен. В частности для профилирования CPU теперь вполне достаточно утилиты perf. Чтобы ею воспользоваться даже не нужно ни с чем линковаться. Всё нужное уже есть в ядре Linux:
$ perf record -g -F 99 -p `pgrep envoy`
^C[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.694 MB perf.data (1532 samples) ]Результат сохраняется в файл perf.data, формат которого понятен pprof (начиная с некоторой версии):
$ pprof -http=localhost:8080 perf.dataТо есть результат совершенно идентичен варианту с использованием gperftools.
Однако имеются подозрения, что perf.data содержит даже больше полезных данных, чем pprof позволяет отобразить. В частности я не смог найти, как сделать разбивку стеков по потокам. Если кто-то знает, напишите, пожалуйста, в комментариях. Такая разбивка может быть полезна для обнаружения узких мест, когда несколько потоков делегируют какую-то работу одному единственному потоку и перегружают его. Пока что для меня незаменимым инструментом для таких случаев служит набор скриптов Брендана Грегга: https://github.com/brendangregg/FlameGraph. Если их применить к имеющемуся файлу perf.data, то получим flamegraph, в котором можно различить три потока — один главный и два рабочих.
$ perf script --input=perf.data | ./FlameGraph/stackcollapse-perf.pl > out.perf-folded
$ ./FlameGraph/flamegraph.pl out.perf-folded > perf.svg
Впрочем, глядя на такой flamegraph, далеко не всегда мы можем догадаться, что имеем дело с блокировками на перегруженном потоке. Полезнее может оказаться картинка с неработающими потоками, то есть ожидающими снятия какой-нибудь блокировки. Опять же, всё нужное для этого есть в ядре Linux — речь идёт о eBPF. Инструментализация кода не требуется. Только убедитесь, что в вашей системе установлен пакет с инструментами для “BPF Compiler Collection”. В Fedora он называется bcc-tools.
$ /usr/share/bcc/tools/offcputime -df -p `pgrep envoy` 30 > out.stacks
$ ./FlameGraph/flamegraph.pl --color=io --title='Off-CPU Time Flame Graph' < out.stacks > off-cpu.svgДля примера приведу два графика для Envoy под большой нагрузкой запущенного с четырьмя и девятью рабочими потоками.
Это 4 потока
Это 9 потоков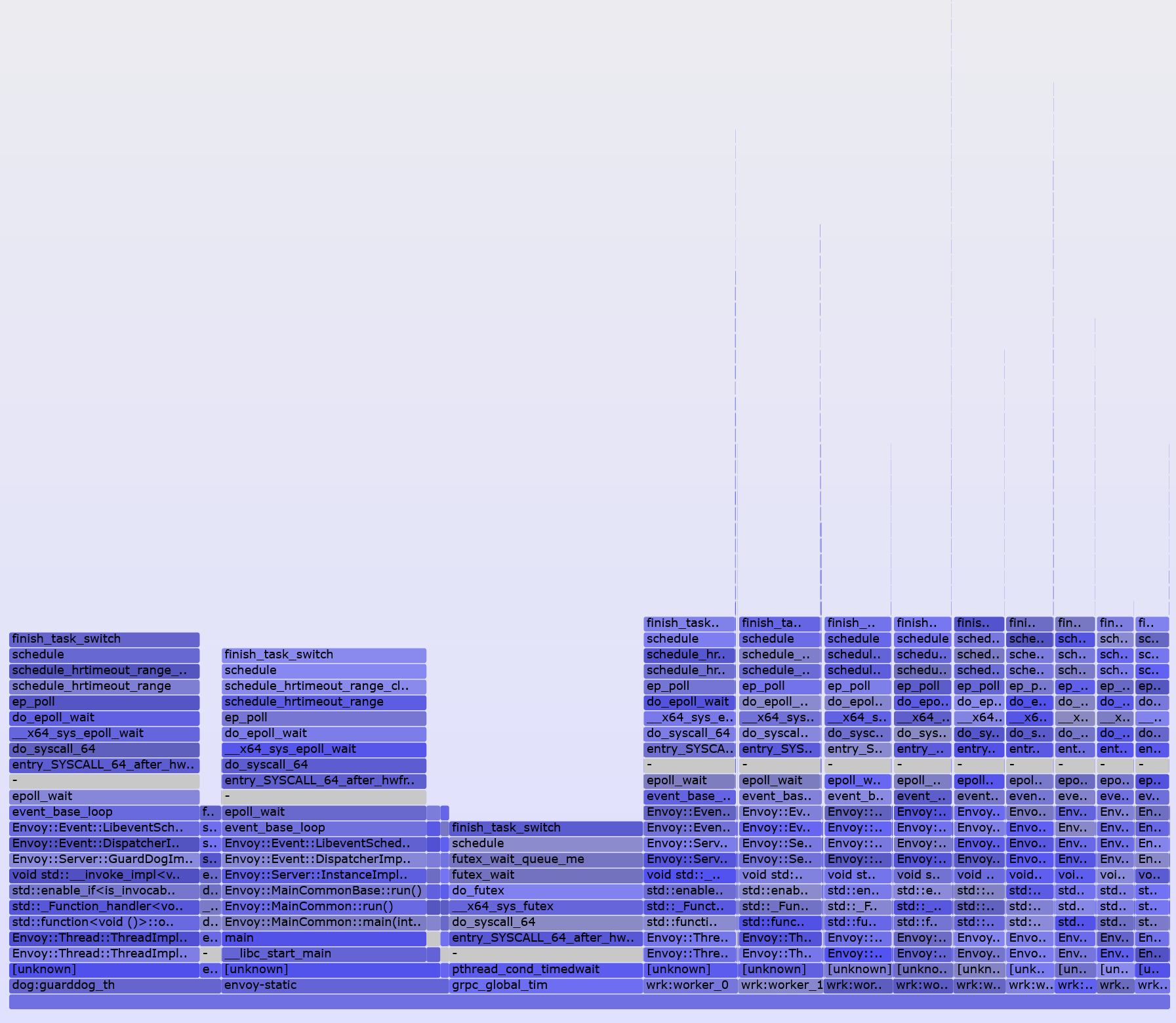
Можно заметить, что при большем количестве рабочих потоков оные всё большую часть времени ничегонеделания бесполезно ждут в цикле событий вместо того, чтобы с пользой ждать, например, возврата из других системных вызовов. При том, что запросы к серверу остаются необслуженными. Это как раз результат эксперимента по передаче части работы от рабочих потоков одному специализированному потоку — плохая идея в общем случае.
А вот с профилированием памяти не всё так радужно, хотя и тут можно кое-чего добиться полагаясь только на eBPF и на утилиту stackcount из bcc-tools. Для того, чтобы получить flamegraph в стиле pprof, надо сделать следующее
$ sudo /usr/share/bcc/tools/stackcount -p `pgrep envoy` -U "/full/path/to/envoy:_Znwm" > out.stack
$ ./FlameGraph/stackcollapse.pl < out.stacks | ./FlameGraph/flamegraph.pl --color=mem --title="operator new(std::size_t) Flame Graph" --countname="calls" > out.svgstackcount группирует вызовы к некоторой функции по идентичным стекам вызовов к ней (stack traces) и суммирует их. Обратите внимание на странно выглядящий параметр -U "/full/path/to/envoy:_Znwm". Он указывает на некоторую функцию в пространстве пользователя (в противоположность параметру -K, который может указать на функцию в пространстве ядра). В общем случае он задаётся как -U lib:func, где lib — это имя библиотеки, а func — имя функции в том виде, как оно выглядит выводе objdump -tT /path/to/lib. В нашем случае _Znwm — это не что иное как void* operator new(std::size_t). А путь к исполняемому файлу вместо имени библиотеки указан потому, что есть нюанс — Envoy статически слинкован с tcmalloc. К сожалению, из документации вы не узнаете о таких мелочах.
Чтобы понять как C++ компилятор видоизменит (mangle) нужную вам функцию, воспользуйтесь вот таким однострочником
$ echo -e "#include <new>n void* operator new(std::size_t) {} " | g++ -x c++ -S - -o- 2> /dev/null
.file ""
.text
.globl _Znwm
.type _Znwm, @function
_Znwm:
.LFB73:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movq %rdi, -8(%rbp)
nop
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE73:
.size _Znwm, .-_Znwm
.ident "GCC: (GNU) 10.2.1 20201016 (Red Hat 10.2.1-6)"
.section .note.GNU-stack,"",@progbitsОбратите внимание, что имя функции будет разным на 32 и 64 разрядных платформах из-за разного размера size_t. Кроме того void* operator new[](std::size_t) — это отдельная функция. Как, впрочем, и malloc() с calloc(), которые будучи C-функциями свои имена не меняют.
Снова должен с сожалением констатировать, что stackcount покажет не сколько именно памяти выделялось в той или иной функции, а как часто. Но зато этот метод анализа применим даже в тех программах, которые не полагаются на готовые менеджеры памяти, а реализуют для работы с кучей свой, родной и ни на что не похожий, бесконечно оптимизированный “велосипед” (конечно же, с отсутствующими при этом средствами анализа расхода памяти).
Чтобы ответить на вопрос “сколько”, нужен инструмент, который будет суммировать аргументы вызовов malloc() или new, а лучше все сразу. То есть что-то вроде этого. В идеале хотелось бы, чтобы во внимание принимались ещё free() и delete, но это уже из области магии. Если кто-то уже реализовал такое на eBPF, отпишитесь, пожалуйста, в комментариях.
В качестве заключения хочу порекомендовать всем, кого интересует тема производительности и оптимизации внимательно изучить блог Брендана Грегга. Там бездна полезной информации.