Быстрое чтение CSV в C# (fast read CSV)
Уже не первый год пользуюсь своим универсальным конвертером CSV файлов в БД SQL Server – ImportExportDataSql, который имеет ряд полезных функций, необходимых любому разработчику БД MSSQL, например: перенос данных с одной БД в другую через SQL скрипт, выгрузка структуры БД, загрузка файлов в БД, выгрузка файлов из БД на диск (кроме этого, обработка типа varbinary работает в CSV), объединение SQL выборок в один файл и др.
ImportExportDataSql бесплатный, портативный, без рекламы и оповещает об обновлениях.
Поставил себе цель, ускорить загрузку CSV в БД MSSQL быстрее, чем это делает стандартная утилита “bcp”. В моем приложении используется стандартный способ чтения CSV файлов, через System.IO.StreamReader методом ReadLine, но я уверен, что стандартные способы не самые производительные.
Итак, сравним несколько библиотек, написанных на языке C#, которые читают CSV файлы и разбивают строку на массив строк (колонки). Результаты тестов будут складываться по нескольким параметрам:
-
время выполнения
-
максимальное потребление оперативной памяти
-
средняя нагрузка CPU (%)
Подробные результаты тестов, а также исходники для тестирования описанных способов, приведены в конце статьи.
Как проводилось тестирование?
Один и тот же CSV файл обрабатывался в цикле 10 раз подряд одним и тем же способом. Пока работает цикл, в отдельном потоке таймер раз в 300 милисекунд собирает статистику потребления памяти и нагрузку процессора, чтобы в конце посчитать средние показатели (в таблице результатов они обозначены AVG).
private static void OnTimedEvent(Object source, ElapsedEventArgs e)
{
try
{
int processCPU = Convert.ToInt32(_processCPUCounter.NextValue() / Environment.ProcessorCount);
lock (_lock)
{
_processUsageList.Add(processCPU);
_memoryUsageList.Add(Process.GetCurrentProcess().WorkingSet64 / 1024);
}
}
catch (Exception ex)
{
System.Console.WriteLine("ERR OnTimedEvent: " + ex.Message);
}
}Все тесты проводились в сборке “Release”.
Тесты проводились на прогретом железе, т.е. приложение запускалось несколько раз, пока время обработки файла в цикле будет примерно одинаково.
Для каждого теста оставлял в коде только один способ тестирования и прогонял их по очереди отдельными exe файлами. Итоги записывал в таблицу сравнения результатов.
Способ 1. Загрузка CSV с многострочными полями
Для начала хотелось бы рассказать о том, в чем преимущество ImportExportDataSql перед стандартными способами загрузки CSV в SQL Server (утилита bcp или операция BULK INSERT).
-
загрузка больших CSV файлов блоками (1 блок = 1 транзакция = N строк, где N указывает сам пользователь)
-
загружать CSV/Excel файлы с возможностью настройки полей, а также с ограничением количества обрабатываемых строк (удобно при отладке)
-
поля в заголовке не привязаны к порядковому номеру, например: файлы с заголовками “Фамилия;Имя;Отчество” и “Имя;Отчество;Фамилия” будут обработаны одинаково, независимо от порядка полей. В “bcp” это можно реализовать только с использованием файлов форматирования, а в BULK INSERT нельзя менять последовательность полей
-
загружать несколько CSV файлов в БД из одной папки, используя маску файлов
-
автоматическое создание таблицы, если её не существует, в том числе во временные глобальные таблицы (рассмотрим в примере ниже). Таблица создается в режиме “Простой импорт”, в остальных режимах таблица не создается.
-
возможность добавлять свои поля, которых нет в CSV файле с помощью встроенных функций
-
поддерживается обработка varbinary полей
-
возможность добавлять свои поля, которых нет в CSV файле с помощью встроенных функций
-
фильтр полей в режиме “Поиск по заголовку”
Список встроенных функций обработки CSV в ImportExportDataSql
-
NEWID – генерация GUID значения
-
ROWNUM – порядковый номер записи
-
EXCELROWNUM – номер строки в CSV/Excel файле
-
FILENAME – имя обрабатываемого файла
В качестве примера, будем использовать текстовый файл с именем multiline.csv, со следующим содержимым:
Товар;Группа;Цена;Примечание
Ремень Класика;Аксессуары/Ремни;1190;"Это пример
""многострочного"" примечания
с двойными кавычками"
Ремень Элегантность;Аксессуары/Ремни;730;"Пример однострочного примечания"Рассмотрим загрузку CSV файла через утилиту bcp
При загрузке CSV файла, приведенного в примере, через утилиту bcp или операцией BULK INSERT мы можем получить несколько ошибок. Например, выполним команду:
bcp.exe ##multiline_csv in "D:tmpmultiline.csv" -q -c -C ACP -S localhost -E -t ";"В результате мы получим ошибку Недопустимое имя объекта “##multiline_csv”:
SQLState = S0002, NativeError = 208
Error = [Microsoft][ODBC Driver 17 for SQL Server][SQL Server]Недопустимое имя объекта "##multiline_csv".
SQLState = 37000, NativeError = 11529
Error = [Microsoft][ODBC Driver 17 for SQL Server][SQL Server]Не удалось определить метаданные, поскольку каждый кодовый путь вызывает ошибку. (См. предыдущие ошибки.)Создадим таблицу ##multiline_csv запросом:
create table ##multiline_csv (
column1 varchar(8000),
column2 varchar(8000),
column3 varchar(8000),
column4 varchar(8000)
)После этого загрузим снова наш файл с помощью той же команды и получим результат
Starting copy...
3 rows copied.
Network packet size (bytes): 4096
Clock Time (ms.) Total : 1 Average : (3000.00 rows per sec.)На первый взгляд, кажется, что команда успешно выполнилась и данные загрузились в БД. Обратим внимание, на сообщение 3 rows copied – это правильный результат. Но как записи сохранились в БД? Проверим результат запросом SELECT * FROM ##multiline_csv:

Первая строка с заголовком загрузилась верно. А на второй строке в поле column4 мы видим только “Это пример, хотя должны были увидеть Это пример “многострочного” примечания с двойными кавычками:

Как видим, результат неверный и такую проблему не решить на уровне bcp или BULK INSERT. Остается только править файл вручную и искать эти двойные многострочные значения избавляясь от многострочности или приводя все поля к двойным кавычкам.
Загрузка CSV файла с помощью ImportExportDataSql
С помощью ImportExportDataSql можно избавиться от ошибок, описанных выше, не изменяя CSV файл.


Способ 2. System.IO.StreamReader (метод Split)
Это стандартный и самый простой способ чтения файлов, который имеет один недостаток при вызове метода ReadLine(): возникает ошибка OutOfMemoryException, если имеется очень длинная строка в файле.
Данный способ используется чаще всего при разработке приложений. В этом тесте мы будем использовать метод Split, который разбивает строку на поля по указанному символу разделителю. По результатам, данный способ показал 4 место по времени выполнения и 3 место по использованию памяти. Я был немного удивлен, что данный способ далеко не самый быстрый.
Способ 3. LumenWorks.Framework.IO.Csv.CsvReader
Подробности описания данного метода см. здесь. По итогам теста, данный способ немного быстрее стандартного метода, но это происходит только с файлом, который участвует в тесте (размером 557Мб, 44 столбца).
Я протестировал обработку другого файла, размером 795 Мб и этот метод оказался самым быстрым. Файл размером 795 Мб (32 столбца) обрабатывался в среднем за 2233 мс.
Возможно, увеличение количества столбцов в CSV так сильно повлияло на работу этой библиотеки и производительность упала в 2 раза.
Способ 4. FileHelpers (https://www.filehelpers.net)
Данная библиотека не умеет обрабатывать CSV отдельно по строкам, вместо этого она пытается загрузить весь файл в объект, который должен быть заранее описан в виде отдельного класса или структуры. В связи с этими недостатками, библиотека показала самые худшие результаты обработки больших CSV файлов. FileHelpers не только самая медленная, но еще и очень сильно потребляет память, а диагностика нам показывает, что сборщик мусора вызывается постоянно.
На картинке ниже сравниваем способы 2 (слева) и 4 (справа):
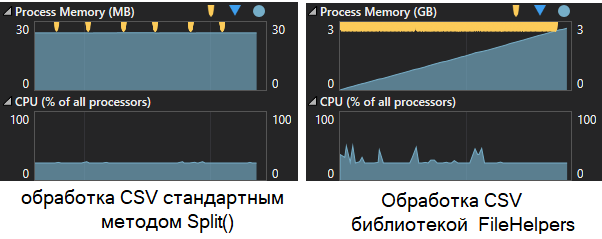
Обратите внимание на график Process Memory, на желтые флажки, которые означают запуск сборки мусора. Слева всего 6 раз вызывается GC, а справа бесчисленное количество раз, что сказывается на производительности.
При обработке файла размером 795Мб сначала тест провалился. Во первых, нехватает памяти, во-вторых начинает работать процесс “Отчет об ошибках Windows”

Чтобы избежать нехватки памяти добавил принудительный вызов сбора мусора:
private static void FileHelpersTest(string fileName, out int countRows)
{
var engine = new FileHelpers.FileHelperEngine<Customer>();
Customer[] c = engine.ReadFile(fileName);
countRows = c.Length;
c = null;
GC.Collect();
}После этого тест прошел и я увидел, что данный способ для обработки файла 795 Мб требуется в 10 раз больше памяти.
Для моего приложения этот способ совсем не подходит, так как я заранее не знаю сколько полей будет в CSV и определять заранее класс или структуру неудобно. Возможно, популярность библиотеки (судя по количеству звезд на github), объясняется не производительностью, а другими возможностями. Если найдутся разработчики, которые читают эту статью и используют FileHelpers, напишут нам в комментариях, за что им нравится эта библиотека.
Способ 5. fastCSV
Подробности описания данного метода см. здесь. Проект выложен на github. Исходники данной библиотеки работают по такому же принципу, как и FileHelpers (способ 4), т.е. обрабатывается файл целиком и нужно заранее создать класс и описать все свойства для маппинга. Так как код этой библиотеки не сложный и он показал значительно лучшую производительность по сравнению с FileHelpers (см. “original” в таблице сравнения результатов), то я изменил код и сделал методы чтения CSV построчно, без маппинга в класс (см. “inline” в таблице сравнения результатов). Код fastCSV с методом “inline” можете скачать из исходников (см. ссылку в конце статьи).
В итоге, для тестового CSV файла размером 795Мб, данный способ оказался самым быстрым и менее затратным по CPU и оперативной памяти. С помощью этой библиотеки действительно можно значительно повысить скорость чтения CSV.
В случае, если необходимо маппить CSV с объектом, то этот вариант в 2 раза быстрее, чем FileHelpers и менее затратный в памяти, чем FileHelpers.
Способ 6. Memory Mapped Files
Этот способ я выбрал напоследок, чтобы проверить его на деле. Данный способ бывает полезен, если нужно работать с файлом параллельно из нескольких потоков или процессов. На практике я его никогда не использовал, но в свои тесты добавил. По результатам видно, что памяти потребляется почти столько же (немного меньше), чем размер файла.
Таблица сравнения результатов
Тесты проводились на двух файлах. Первый файл слева (до знака /), второй файл справа (после знака /):
размер файла – 557 Мб / 795 Мб
количество строк – 4 496 263 / 3 697 693
количество полей 44 / 32
Способ Multiline Csv Reader реализован в моем приложении ImportExportDataSql, который использует класс System.IO.StreamReader метод ReadLine (в таблице мой метод до оптимизации кода) и видно, что он немного быстрее метода Split().
|
Multiline Csv Reader |
StreamReader (Split) |
||||||
|
original |
inline |
||||||
|
AVG elapsed (ms) |
5307 / 5682 |
5527 / 6034 |
2404 / 5096 |
59402 / 32909 |
21872 / 14697 |
3630 / 4005 |
4998 / 5293 |
|
MAX elapsed (ms) |
5599 / 5778 |
6040 / 6165 |
2585 / 5162 |
71378 / 34788 |
24103 / 15827 |
3775 / 4099 |
5781 / 6189 |
|
AVG Memory usage (KB) |
32713 / 29693 |
31452 / 30182 |
32161 / 30963 |
4842975/ 3642521 |
4287987 / 2939645 |
30914 / 29935 |
439530 / 457219 |
|
MAX Memory usage (KB) |
35684 / 30652 |
33480 / 30428 |
35956 / 33848 |
9409732/ 7232620 |
8307932 / 5644120 |
33352 / 32116 |
841908 / 843816 |
|
AVG CPU usage (%) |
12 / 12 |
11 / 15 |
10 / 14 |
12 / 12 |
13 / 12 |
11 / 18 |
12 / 13 |
Заключение
Подходы с использованием библиотек LumenWorks и fastCSV показали наиболее высокие показатели чтения CSV файлов. Результат зависит от размера файла и количества полей в нем.
FileHelpers показал самый худший результат по быстродействию и занимаемой памяти. Вместо FileHelpers необходимо использовать библиотеку fastCSV, которая также может маппить строки в объекты (способ “original”).
Во всех OpenSource библиотеках, к сожалению, нет поддержки чтения многострочных полей. В ImportExportDataSql я буду внедрять fastCSV, но сперва добавлю чтение многострочных полей и изучу код подробнее.
Возможно, единственный способ еще сильнее повысить производительность чтения больших CSV файлов, использовать многопоточность, но готовых алгоритмов я пока не нашел, поэтому по окончании однопоточных оптимизаций займусь многопоточностью. О дальнейших оптимизациях, проводимых в ImportExportDataSql буду сообщать в новых статьях.
Ссылки
Исходники для тестирования описанных способов, приведенных в настоящей статье
Статья с подробным описанием ImportExportDataSql
Сообщество VK для поддержки пользователей и желающих пообщаться с автором.