DLS проект за три дня или WEB проект по детекции изображений
Цель данного сообщения поделиться своими впечатлениями о написании проекта, от реализации которого я получил долю адреналина и помочь студентам DLS в их проектах, выбравшим тему детекции. Да и вообще – поделиться идеями.
Небольшое вступление
С началом пандемии моя жизнь круто изменилась. Как и многих остальных, меня отправили на удаленку. В это же время, инвестиции в проект резко уменьшились и у меня оказалось больше свободного времени. Стал повышать самообразование, прошел два-три курса на степике и там же заметил курс Школы Глубокого обучения Deep Learning School или сокращенно DLS. По ходу обучения прошел параллельно курс NLP от Huawei, начал курс в Школе-IT от СБЕР. В общем решил немного сместить вектор деятельности в сторону AI. И вот дошел до финального проекта по DLS. Тут еще, на носу соревнование по Альфа-войнам. В общем еще тот Осенне-зимний марафон. Но – это тема другой статьи. Так вот, нужно форсировать события, чтоб все успеть.
День первый
Пару слов о себе: у меня хороший опыт бэкенд разработки на PHP, но последний мой проект был реализован на питоне. Так же мне приходилось реализовывать разные проекты или их части на С/С++, lua и даже js. Последний, я намного недолюбливаю со времен IE 3.0, когда не было ни какой отладки и код постоянно падал. С тех пор, я всеми правдами и не правдами стараюсь уйти от фронт-энда. Но, сейчас требования времени таковы, что без применения AJAX – просто ни куда, так что приходится знать JQuery в минимальном объеме.
Я немного отвлекся, но чтоб было более понятно, когда были объявлены темы выпускных проектов, то выбор однозначно пал на WEB проект. Как сделать WEB часть я знал наперёд, были не раз реализованы похожие паттерны и даже по этой теме выступал на Конференции
Тема проекта “Детекция изображений“.
Алгоритм был прост:
-
найти готовое решение
-
прикрутить WEB морду
Быстро сказка сказывается, да не скоро дело делается…
И вот, набираешь слово detection в строке поиска на гитхабе, то выходит 100500+ проектов, фильтруешь по питону – увы чуть меньше, но все же но больше 50 тыс. Голова идет кругом. После просмотра лекции и семинаров по детекции в примерах были даны два ноутбука: nvideo_ssd и mmdetection. Решил оттолкнуться от знакомого. Хотя домашних заданий по детекции не было.
Запускаю первый ноутбук на коллабе, и супер!! – все получилось. Ну, думаю, все в порядке, сейчас за пять минут прикручу WEB морду… Да, но оказалась, маленькая загвоздочка: все работало с GPU, а мой виртуальный хостинг имел в своём распоряжении только CPU. Перевожу коллаб в режим CPU и пытаюсь сделать так, чтоб хоть что-то задышало. Увы, после двухчасовых попыток изучения исходников и разных модификаций понял – что это гиблое дело. Возможно, но сложно.
Перехожу к ноутбуку mmdetection. Опять, все запустилось с первого раза в режиме GPU. Еще часа два-три потребовалось настроить режим CPU. Первая маленькая Победа!
День второй
Почти весь второй день я занимался инсталляцией mmdetection на виртуальном хостинге. Инструкция по инсталляции немного отличалась от суровой реальности. В readme основной акцент был сделан на использование GPU, а про CPU одна лишь строчка. Пришлось установить кучу пакетов и библиотек, пере-инсталлить… В общем в конце первой половины дня, я как-то запустил демо приложение mmdetection.py, которое поставлялось в пакете.
Теперь перехожу к WEB части. первой мыслью было использовать использовать hhtp server из стандартной поставки питона, но как потом оказалось, там какой-то гемор с загрузкой файлов, по этому решил использовать уже проверенный в бою фреймворк pyramid. Это минималистичный WEB-фреймворк на питоне. Но, самое главное – это сделать index.html который будет отправлять загружаемые картинки и показывать результаты.

Алгоритм работы index.html :
-
Пользователь через AJAX загружает картинку на сервер
-
WEB скрипт принимает картинку, преобразует её в png формат и сохраняет её, присвоив ей уникальное имя. Уникальное имя состоим из уникального идентификатора и типа файла. Пример: sid = 123, уникальное имя 123.png
-
После загрузки файла, клиентский Js скрипт через AJAX по таймеру проверяет наличие файла [sid].out.png.
-
Если файл [sid].out.png существует, то Js скрипт показывает его.
Ура! Моя моделька как-то задышала. Эту часть я отлаживал без WEB сервера, подсунув результат файл [sid].out.png ручками. Осталось прикрутить WEB часть и саму детекцию.
День третий
третий день прошел менее продуктивно. WEB часть была реализована не более чем за час. Чего там делать: принять POST файл и сохранить его на диске. С загрузкой файлов в пирамиде я не работал, по этому пришлось немного повозиться.
Первые подводные камни начались, когда я вызывал из WEB скрипта скрипт распознавания.
А почему нельзя сделать все в одном скрипте? Дело в том, что распознавание на CPU занимает 20-30 сек, а то и минуту и соединение может оборваться. По этому и придумана асинхронная обработка. WEB скрипт запускает бэдграундовский процесс, который осуществляет детекцию и сразу после этого WEB скрипт возвращает клиентскому приложению (WEB браузеру) номер сессии или уникальный случайный идентификатор, который далее WEB браузер использует для опроса готовности результата.
Так вот, скрипт детекции запускался, но отказывался работать. И в логи писал, и по разному моделировал запуск скрипта. Оказалось, что если запускать скрипт из консоли то используется одно окружение, а запуск одного скрипта из другого скрипта – совсем другое окружение. А так как, при инсталляции mmdetection требовалась miniconda, то и все питоновкие пакеты были проинсталлированы в окружении miniconda и это окружение эмулировалось в консоле. Заменив вызов стандартного интерпретатора питона на вызов питона из пакета miniconda – все заработало.
Следующий подводный камень, с которым я столкнулся: это когда скрипт детекции уходит в бэкграунд, то он переставал выполняться. Этого победить я так и не смог. Просидев часа полутора над этой проблемой, я оставил всё как есть, только отсоединил вновь запускаемый скрипт от родительского процесса. В результате оставались зомби процессы. Но это не так страшно, и их было мало. Со временем Z-процессы исчезают. Зомби процесс – это пустая строчка в таблице processlist. Когда их много, то это состояние может повлиять на работу планировщика задач, и будет креш, если processlist переполнится. Но один-два Z-процессf – это вполне нормально.
А как надо было сделать в реальный продакшен? Для реализации продакшена, я бы использовал очередь, в которую записывал бы уникальный номер sid, а на другой стороне очереди по таймоуту запускался бы скрипт, который читал бы очередь и если в ней были бы какие-либо данные, то он все отрабатывал бы. Как то так:
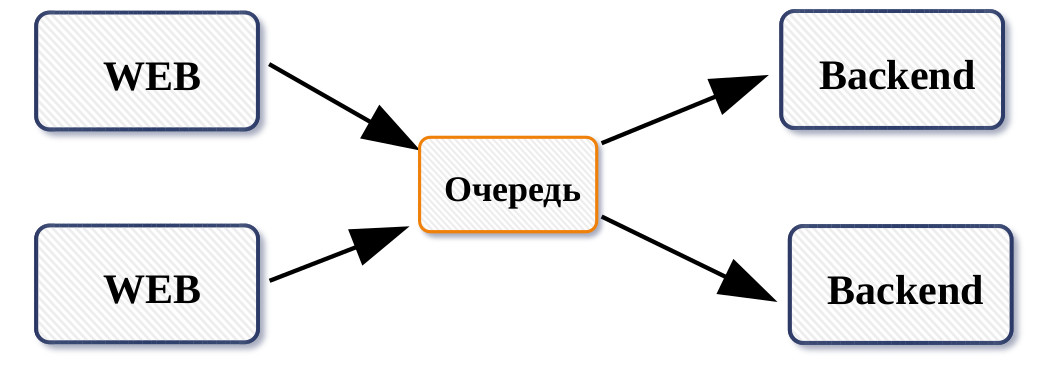
К концу дня у меня был уже работающий прототип.
Конечный алгоритм
-
Пользователь через AJAX загружает картинку
-
WEB скрипт принимает картинку, преобразует её в png формат и сохраняет её, присвоив ей уникальное имя. Уникальное имя состоим из уникального идентификатора и типа файла. Пример: sid = 123, уникальное имя 123.png
-
WEB скрипт возвращает клиентскому приложению (Js скрипту) уникальный идентификатор sid, который будет необходим для опроса шаг 7 и запускает таймер опроса.
-
Далее WEB скрипт запускает скрипт определения предметов на картинке: mmdetectionl.py и передает ему в качестве параметров уникальный идентификатор и точность выбора.
-
Скрипт детекции по уникальному идентификатору sid определяет имя файла и осуществляет на нем детекцию.
-
Результаты детекции mmdetectionl.py сохраняет в виде файла: [sid].out.png: например 123.out.png.
-
После загрузки файла, клиентский Js скрипт через AJAX по таймеру проверяет наличие файла [sid].out.png.
-
Если файл [sid].out.png существует, то Js скрипт показывает его.
Работа алгоритма была изображена на первом рисунке.
Три дня – неужели?
На самом деле я потратил чуть больше. Но, три дня понадобилось на работающий прототип или MVP. То, что я реализовал, мне показалось – мало. Я решил, раз отображаются боксы детекции, значить они должны быть где-то в данных. И стал ковырять данные. Спустя полтора часа я вычленил все нужные мне боксы, осталось понять, к каким классам относятся номера боксов. Покопавшись в исходниках и отладке еще часик я реализовал вывод боксов в виде текста, так как иногда боксы наезжают друг на друга и не разобрать, что же там программа на детектировала.
Еще денек у меня ушел на ползунок четкости. Часа полтора возился с плагином JQuery, и пять минут с реализацией. Запустилось со второго дубля. Добавил новый параметр в исходный HTTP запрос и вызов программы детекции.
Результат
Не судите за код на js, знаю что говнокод. С кодом python чуть получше, хотя оформлено не по PES
Ссылка га проект Дизайн – слово на букву Г, нет времени и задачи по дизайну не стояло…
Проект может не работать. Могут быть две причина: либо я в нем что-то улучшаю, тогда обращайтесь в telegram @akalend Вторая : это тестовый сервер от работы, и его могут в любое время забрать под другие нужды или меня уволить. Любые замечания приветствуются. Надеюсь это кому-то поможет.

PS
для тех кто делает телеграмм бота – принцип такой же.