RESTinio-0.6.13: последний большой релиз RESTinio в 2020 и, вероятно, последний в ветке 0.6
RESTinio — это относительно небольшая C++14 библиотека для внедрения HTTP/WebSocket сервера в C++ приложения. Мы старались сделать RESTinio простой в использовании, с высокой степенью кастомизации, с приличной производительностью. И, вроде бы, пока что это получается.
Ранее здесь уже были статьи про RESTinio, но в них речь больше шла о том, что и как было сделано в потрохах библиотеки. Сегодня же хочется рассказать о том, что появилось в свежей версии RESTinio, и зачем это появилось. А так же сказать несколько слов о том, почему этот релиз, скорее всего, станет последним большим обновлением в рамках ветки 0.6. И о том, чего хотелось бы достичь при работе над веткой 0.7.
Кому интересно, милости прошу под кат.
Главной целью, которую мы преследовали начиная в 2017-ом году проект RESTinio, было упрощение написания HTTP-точек входа в C++ приложения. И одним из способов такого упрощения было заимствование лучшего из того, что нас окружало. В частности, в RESTinio мы сделали аналог роутера запросов из ExpressJS. В итоге express_router стал чуть ли не наиболее востребованной из возможностей RESTinio.
Но в ExpressJS кроме роутера есть еще важная штука: middleware. И вот её-то мы изначально в RESTinio и не стали переносить.
Сперва эта функциональность нам была не нужна. Но по мере взросления RESTinio мы стали сталкиваться с ситуациями, в которых что-то похожее на middleware из ExpressJS было бы полезным. А раз так, то захотелось эти самые middleware поиметь и в RESTinio.
Что оказалось далеко не таким простым делом, как хотелось бы. Но давайте обо всем по порядку.
Цепочки из синхронных обработчиков
Итак, начиная с версии 0.6.13 обработчики запросов в RESTinio можно выстраивать в цепочки. И такие обработчики будут последовательно вызываться для обработки очередного запроса. Движение по цепочке от обработчика до обработчика происходит пока все они возвращают специальное значение not_handled. Если же какой-то из обработчиков возвращает accepted или rejected, то обработка запроса прекращается и оставшиеся в цепочке обработчики не вызываются.
Давайте представим себе, что прежде чем начать обрабатывать запрос, нам нужно сделать три действия:
- залогировать сам запрос и какие-то его параметры;
- проверить наличие и значения нужных нам HTTP-заголовков;
- проверить аутентификационные параметры пользователя (если таковые представлены) и удостовериться, что у пользователя есть необходимые права.
Каждое из этих действий теперь может быть представлено в виде отдельного обработчика запросов:
auto incoming_req_logger(const restinio::request_handle_t & req)
{
... // Логируем запрос.
// Разрешаем запустить следующий обработчик в цепочке.
return restinio::request_not_handled();
}
auto mandatory_fields_checker(const restinio::request_handle_t & req)
{
... // Выполняем нужные проверки.
if(!ok) {
// Отсылаем отрицательный ответ и прерываем цепочку.
return req->create_response(restinio::status_bad_request())
...
.done(); // Здесь возвращается accepted.
}
// Разрешаем запустить следующий обработчик в цепочке.
return restinio::request_not_handled();
}
auto permissions_checker(const restinio::request_handle_t & req)
{
... // Проверяем пользователя и его права.
if(!ok) {
// Отсылаем отрицательный ответ и прерываем цепочку.
return req->create_response(restinio::status_unauthorized())
...
.done(); // Здесь возвращается accepted.
}
// Разрешаем запустить следующий обработчик в цепочке.
return restinio::request_not_handled();
}
auto actual_processor(const restinio::request_handle_t & req)
{
... // Основная обработка запроса.
return restinio::request_accepted();
}Для того, чтобы выстроить эти обработчики в цепочку мы должны сделать несколько шагов.
Во-первых, нужно задекларировать новый тип обработчика запросов в свойствах сервера. В составе RESTinio доступно два готовых к использованию типа, один из которых мы и посмотрим в данном примере.
Итак, поскольку количество элементов в цепочке у нас строго фиксировано, то используем fixed_size_chain_t:
// Этот заголовочный файл нужно подключать явным образом.
#include <restinio/sync_chain/fixed_size.hpp>
...
struct my_traits : public restinio::default_traits_t {
using request_handler_t = restinio::sync_chain::fixed_size_chain_t<4>;
};Во-вторых, саму цепочку обработчиков нужно сформировать и отдать серверу при старте:
restinio::run(restinio::on_this_thread<my_traits>()
.port(...)
.address(...)
.request_handler(
// Перечисляем обработчики в порядке их вызова.
incoming_req_logger,
mandatory_fields_checker,
permissions_checker,
actual_processor)
...
);Вот, собственно, и все.
Почему цепочка из синхронных обработчиков?
RESTinio строился с прицелом именно на асинхронную обработку запросов. Но добавленные в версию 0.6.13 цепочки обработчиков отрабатывают только синхронно. Почему так?
Тут надо зайти издалека.
Начнем с того, что для RESTinio любой обработчик запроса выглядит как синхронный.
Давайте, для простоты, рассмотрим случай, когда RESTinio запускается на одной рабочей нити. На этой нити RESTinio делает все: слушает серверный сокет, принимает новые подключения, вычитывает данные из принятых подключений, разбирает прочитанные данные, вызывает обработчик для полностью принятых запросов, записывает исходящие данные, контролирует тайм-ауты…
Соответственно, когда RESTinio вызывает на этой рабочей нити обработчик запроса, то нить, фактически, блокируется до тех пор, пока обработчик не завершит свою работу. Поэтому-то для RESTinio все обработчики синхронные. Как только вызванный обработчик возвращает управление назад, RESTinio получает возможность продолжить свою работу. При этом RESTinio, по большому счету, все равно, что возвратил обработчик: rejected или accepted.
Разница между синхронностью и асинхронностью важна для программиста, который пишет обработчик запроса. Программист может либо полностью сформировать ответ прямо внутри обработчика (т.е. выполнить create_response()...done()) и тогда обработка будет синхронной. Либо же может делегировать обработку на какой-то другой рабочий контекст, где в конце-концов и будет вызван done().
Так вот, суть в том, что когда обработчик запроса возвращает accepted, то RESTinio не знает, был ли запрос уже обработан полностью. Или же обработка запроса была кому-то делегирована. Или же часть обработки была выполнена сразу, а оставшаяся часть отложена на какое-то время.
Для RESTinio факт возврата accepted из обработчика запросов означает, что пользователь взял на себя ответственность за дальнейшую судьбу запроса. И RESTinio не может строить предположений о том, в каком состоянии находится запрос.
Теперь вернемся к цепочкам.
Цепочка выглядит для RESTinio всего как один обработчик. Собственно, показанный выше fixed_size_chain_t — это объект, метод которого и вызывается RESTinio. А уже внутри этого метода происходит последовательный вызов заданных пользователем обработчиков. Сам RESTinio про этот последовательный вызов ничего не знает, для RESTinio никакой последовательности нет вообще.
Предположим, что один из обработчиков вернул не not_handled, не rejected, а accepted. В каком состоянии находится запрос?
Неизвестно. Возможно, обработка запроса делегирована на отдельный рабочий поток и прямо сейчас на этом отдельном рабочем потоке с запросом что-то уже делают.
Поэтому обработка цепочки сразу же прерывается. Т.к. небезопасно вызывать следующий обработчик в цепочке, если на самом деле с запросом что-то делают на другом рабочем контексте.
Из-за этого в версии 0.6.13 поддерживается только цепочка из синхронных обработчиков. Т.е. эта цепочка вызывается здесь и сейчас, от начала и до конца. Нельзя вызвать первый обработчик из цепочки, затем вернуть управление RESTinio, а потом, где-то и когда-то вызвать второй обработчик из цепочки. Нет, все обработчики из цепочки вызываются здесь и сейчас. И лишь после того, как все они отработают, управление будет возвращено RESTinio.
Значит ли это, что внутри цепочки нельзя делегировать обработку кому-то еще?
Нет. Обработчик может делегировать обработку запроса на какую-то другую нить. Но после этого обработчик должен возвратить accepted и цепочка будет прервана.
Можно ли сделать цепочку из асинхронных обработчиков?
Есть ощущение, что можно. В принципе. Но в рамках работ над версией 0.6.13 и при сохранении совместимости в рамках ветки 0.6 у меня не получилось придумать такого способа. Есть одна смутная и не до конца оформившаяся идея, только вот она требует изменения API RESTinio.
Обмен данными между обработчиками в цепочке
Выстраивание обработчиков в цепочку дело не хитрое. Гораздо сложнее организовать обмен данными между стадиями обработки запросов.
Давайте представим себе, что у нас есть следующая цепочка обработчиков:
- authentification_handler, который проверяет наличие параметров аутентификации клиента и выполняет аутентификацию;
- permissions_checker, который проверяет, есть ли у пользователя права на доступ к запрашиваемому ресурсу;
- admin_access_logger, который логирует доступ пользователя к административным ресурсам;
- actual_processor, который выполняет обработку запроса.
Первый обработчик должен породить некий объект user_permissions, в котором будет содержаться идентификатор пользователя и информация о его правах. Далее этот объект должен использоваться в permissions_checker-е (для проверки возможности доступа к ресурсу) и в admin_access_logger (для фиксации в журнале).
Соответственно, возникает вопрос, как созданный внутри authentification_handler объект сделать доступным в последующих обработчиках?
При поиске ответа на этот вопрос было рассмотрено несколько вариантов. В работу пошел вариант, который позволяет встроить пользовательские данные внутрь RESTinio-вского объекта request_t.
Выглядит это следующим образом.
Сперва пользователь определяет некую структуру/класс, экземпляры которой и должны встраиваться в объект-запрос:
struct user_permissions {...};
...
// Вот эта структура должна быть добавлена в каждый запрос.
struct per_request_data {
user_permissions user_info_;
... // Возможно, что-то еще.
};Далее нужно создать тип т.н. extra-data-factory, т.е. фабрики для этой самой дополнительной информации:
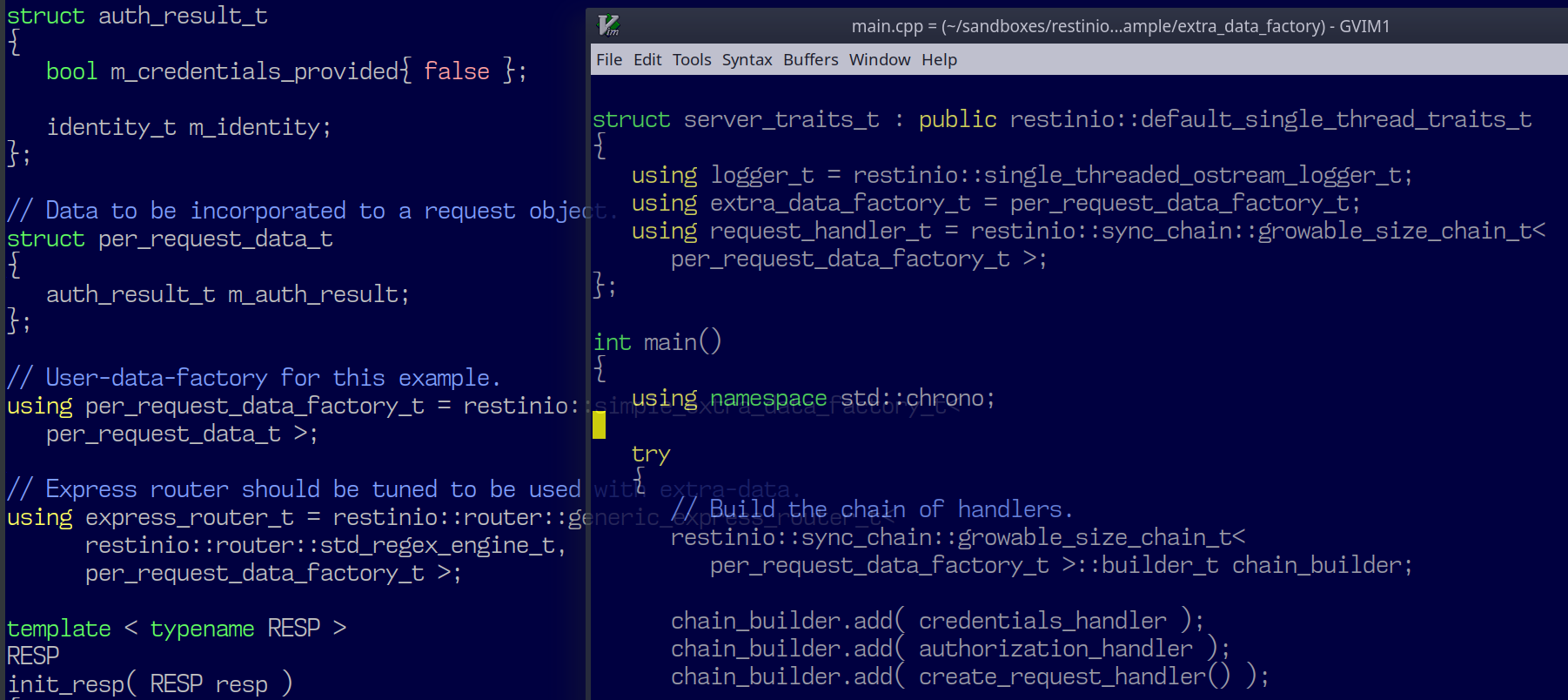
struct my_extra_data_factory {
// Внутри extra-data-factory должен быть тип с именем data_t.
using data_t = per_request_data;
// А также вот такой фабричный метод.
void make_within(restinio::extra_data_buffer_t<data_t> buf) {
new(buf.get()) data_t{};
}
};Затем нужно указать тип нашей фабрики в свойствах сервера:
struct my_traits : public restinio::default_traits_t {
using extra_data_factory_t = my_extra_data_factory;
};Ну и, самое, важное: теперь у обработчиков запросов поменяется формат. Вместо аргумента типа restinio::request_handle_t они будут получать restinio::generic_request_handle_t<per_request_data>:
restinio::request_handling_status_t authentification_handler(
const restinio::generic_request_handle_t<per_request_data> & req);
restinio::request_handling_status_t permissions_checker(
const restinio::generic_request_handle_t<per_request_data> & req);
restinio::request_handling_status_t admin_access_logger(
const restinio::generic_request_handle_t<per_request_data> & req);
restinio::request_handling_status_t actual_processor(
const restinio::generic_request_handle_t<per_request_data> & req);Собственно, это все.
Если наша фабрика не содержит внутри себя никаких данных и является DefaultConstructible типом, то ее экземпляр при запуске сервера даже создавать не нужно — она будет создана автоматически. Но вот если фабрика представляет из себя stateful-объект, который требует инициализации, то пользователю придется создать ее самостоятельно. Например:
// Пусть у каждого запроса будет собственный поток для журналирования.
struct per_request_data {
std::shared_ptr<log_stream> log_;
per_request_data(std::shared_ptr<log_stream> log)
: log_{std::move(log)}
{}
};
// За создание этих потоков будет отвечать фабрика.
class my_extra_data_factory {
std::shared_ptr<logger> logger_;
public:
using data_t = per_request_data;
my_extra_data_factory(std::shared_ptr<logger> logger)
: logger_{std::move(logger)}
{}
void make_within(restinio::extra_data_buffer_t<data_t> buf) {
new(buf.get()) data_t{
std::make_shared<log_stream>(logger_)
};
}
};
struct my_traits : public restinio::default_traits_t {
using extra_data_factory_t = my_user_data_factory;
};
auto logger = std::make_shared<logger>(...);
// Фабрику нужно будет вручную создать перед запуском сервера.
restinio::run(restinio::on_thread_pool<my_traits>(16)
.port(...)
.address(...)
// Вот мы создаем фабрику и передаем её RESTinio.
.extra_data_factory(std::make_shared<my_user_data_factory>(logger))
.request_handler(...)
);Внутри обработчика запросов доступ к дополнительным данным можно получить посредством метода extra_data у объекта generic_request_t:
restinio::request_handling_status_t authentification_handler(
const restinio::generic_request_handle_t<per_request_data> & req)
{
... // Производим аутентификацию.
if(!ok) {
// Шлем отрицательный ответ.
return req->create_response(...)...done();
}
else {
// Сохраняем информацию о пользователе внутри запроса.
req->extra_data().user_info_ = user_permissions{...};
return restinio::request_not_handled();
}
}
restinio::request_handling_status_t permissions_checker(
const restinio::generic_request_handle_t<per_request_data> & req)
{
// Запрашиваем информацию о пользователе с предыдущего шага.
const auto & user_info = req->extra_data().user_info_;
... // Работа с информацией о пользователе.
}Дополнительная информация, generic_request_t<Extra_Data> и совместимость со старым кодом
По сути, начиная с версии 0.6.13, RESTinio работает уже с двумя новыми типами: шаблонным классом generic_request_t<Extra_Data> и шаблонным псевдонимом generic_request_handle_t<Extra_Data> (который есть std::shared_ptr<generic_request_t<Extra_Data>>).
А для того, чтобы такое кардинальное нововведение не поломало ранее написанный код, старые имена request_t и request_handle_t теперь являются всего лишь псевдонимами для generic_request_t<no_extra_data_factory_t::data_t> и generic_request_handle_t<no_extra_data_factory_t::data_t>, где no_extra_data_factory_t — это новый тип для фабрики по умолчанию.
В restinio::traits_t, restinio::default_traits_t и restinio::default_single_thread_traits_t именно no_extra_data_factory_t используется в качестве extra_data_factory_t. Поэтому старый код, который использует имена request_t и request_handle_t, сохраняет свою работоспособность и требует только лишь перекомпиляции.
extra-data и express-/easy_parser_router
Выше уже говорилось, что express_router, сделанный по мотивам ExpressJS, является одной из наиболее востребованных возможностей RESTinio. При этом express_router вводит собственный формат для обработчиков запросов. Соответственно, появление extra-data для запроса сказалось и на express_router-е.
Если программист хочет использовать extra-data с запросами, которые обрабатываются посредством express_router-а, то ему нужно явно указать express_router-у тип фабрики extra-data. Например:
struct my_extra_data_factory { ... };
struct my_traits : public restinio::default_traits_t {
using extra_data_factory_t = my_extra_data_factory;
using request_handler_t = restinio::router::express_router_t<
restinio::router::std_regex_engine_t,
extra_data_factory_t>;
};Вот после этого первым аргументом в обработчик запроса для express_router вместо request_handle_t будет generic_request_handle_t<my_traits::extra_data_factory_t::data_t>.
Тоже самое относится и к easy_parser_router:
struct my_traits : public restinio::default_traits_t {
using extra_data_factory_t = my_extra_data_factory;
using request_handler_t = restinio::router::easy_parser_router_t<
extra_data_factory_t>;
};Теперь можно сказать несколько слов о том, почему же время жизни ветки 0.6 подходит к концу и зачем начинать ветку 0.7.
Причин несколько.
Во-первых, RESTinio с самого начала базировался на библиотеке http-parser. Но теперь, кажется, эта библиотека остается без поддержки. Соответственно, какую бы замену для http-parser мы не приготовили (стороннюю или же собственную), это скажется на списке зависимостей RESTinio. Что является достаточным поводом, чтобы сменить номер версии.
Во-вторых, в коде RESTinio уже обнаружилось несколько просчетов, которые было бы желательно исправить. Но исправления поломали бы совместимость, поэтому пока что эти исправления не вносились. Однако, рано или поздно с этим нужно было бы что-то делать. Так почему бы не сейчас?
В-третьих, есть ряд хотелок, воплощение которых в жизнь, как представляется, слишком затратно в рамках ветки 0.6 с оглядкой на совместимость. К таким хотелкам можно отнести следующие:
- поддержка не только http/1.1, но и http/2, а затем и http/3;
- дополнительный режим работы, в котором RESTinio не загружает весь запрос в память перед вызовом обработчика, а вызывает обработчик по мере загрузки отдельных частей запроса;
- поддержка цепочки асинхронных обработчиков.
Как по мне, так вместе все это образует достаточно увесистый набор причин для того, чтобы оставить ветку 0.6 как есть и пойти вперед.
А есть ли у вас какие-то пожелания к RESTinio?
Поскольку мы стоим на пороге изменений в функциональности RESTinio, то сейчас отличный момент для того, чтобы высказать свои пожелания к RESTinio.
Могу уверить, что любые конструктивные соображения, замечания и предложения будут самым внимательным образом рассмотрены и приняты к сведению.
Сразу скажу, что клиента на базе RESTinio мы за свой счет не потянем. Об этом не просите 🙁 Если только просьба не будет подкреплена материально 😉
В общем, приглашаю всех желающих высказать свои соображения о функциональности, которую хотелось бы видеть в RESTinio, в Issues или Discussions на GitHub. Или в Google-группу. Ну или можно прямо сюда, в комментарии.
2020-й год подходит к концу. Год был, мягко говоря, непростой. Тем не менее, RESTinio живет и развивается. Если не ошибаюсь, нам удалось выкатить порядка десятка релизов и опубликовать здесь несколько посвященных RESTinio статей.
Немалую роль в этом сыграли наши пользователи, которые рискнули выбрать RESTinio для своих задач. А кто-то и нашел время/возможность для обратной связи. Благодаря чему удалось избавить RESTinio от нескольких недостатков и снабдить несколькими фичами.
Так что хочу сказать большое спасибо всем, кто интересуется RESTinio. Ваше внимание очень важно для нас.
И, конечно же, огромное спасибо всем, кто использует RESTinio. Без вас у этого проекта бы не было развития.
Ну и с наступающим Новым Годом!