Как мы роботизировали документооборот крупнейшего европейского ритейлера
В последнее время все чаще слышно про RPA или Robotic Process Automation. С одной стороны, говорят о его эффективности для банковского сектора и крупных корпораций, с другой — про применимость и в среднем, и даже в малом бизнесе. На днях на Хабре вышла обзорная статья про интеллектуальную обработку документов с помощью RPA – и мы подумали, что хабравчанам также будет интересен рассказ про наш опыт реализации такого проекта в деталях.
Он был выполнен для одного из крупнейших ритейлеров в РФ и Европе. Его магазины можно найти везде: в одной только Москве и области их десятки, а по всей России больше сотни. Это фантастическое количество товаров, поставщиков, поставок — и связанного с ними документооборота, которого с каждым месяцем становится больше и больше.

Большая часть документов проходит по ЭДО. Но в нем работают не все поставщики, и бремя сверки бумажной документации перед оплатой ложится на плечи бухгалтеров. Совсем не редки случаи, когда цены в заказах и документах на оплату разнятся, причин расхождения может быть много. При этом объем документооборота растет, и этот процесс превращается в ужасную механическую кабалу для целого штата бухгалтеров-сверщиков.
Идеальный сценарий для RPA! А для нас — отличная возможность показать, как он грамотно и продуктивно реализуется.
С чем предстояло работать
Итак, нам предстояло создать робота, который будет трудиться в одном из звеньев стандартной рабочей схемы любого ритейла. Схема очень простая и расхожая: ритейлер формирует заказ на поставку товаров в свои магазины, после его доставки поставщиком производится приемка и после обработки документов — оплата.

Описанные выше проблемы возникали на этапе обработки документов. На стороне заказчика каждый день на эту задачу тратилось 72 часа. Это 9 полноценных бухгалтерских рабочих дней! Роботизации этого проекта от нас и ждали.

Подробное описание процесса сверки, с которым мы должны были работать:
Итак, что нужно сделать бухгалтеру, чтобы сверить доки? По готовым к сверке заказам в учетной системе формируется еxcel-отчет — реестр заказов с их номерами, номерами приемки, магазином, наличием расхождений по количеству и стоимости и т.д. Чтобы сэкономить время, при работе с бумажными первичными документами бухгалтер выгружает их сканы из ЭХД (поиск в Directum по штрихкоду из отчета). Сканы нужны для того, чтобы сверить цены в заказе с ценами из документа поставщика.
Далее по каждой поставке из отчета бухгалтер проверяет сумму расхождения в учетной системе. Большие расхождения отмечаются в отчете красным цветом, если расхождений нет или они незначительные, то поставка сразу отправляется бухгалтером на оплату. По бумажным документам бухгалтер сверяет цены попозиционно, если они отличаются — в систему вносятся цены из документа.
По итогам проверки бухгалтер формирует в учетной системе акты расхождений, куда попадают все отмеченные красным строки. Эти акты затем отправляются специалистам по товарному предложению на согласование: бухгалтер не в курсе согласованных с поставщиком цен, поэтому должен получить подтверждение их корректности. Если расхождения согласованы, то они отправляются на оплату. Если нет, то с поставщиком выясняются причины отклонений.
После согласования бухгалтер выполняет процесс сопоставления счетов-фактур в системе. Этот процесс может занимать достаточно много времени, эта функция работает нестабильно.
Как видите, большая часть этого процесса — механическая рутина. Идеальная цель для автоматизации! Однако классический путь доработки ERP-системы с интеграцией ее с СХД был заказчику закрыт: бэклог команд, занимающихся сопровождением и развитием этих систем, был расписан на месяцы вперед, а доработка системы сложна и дорога. В общем, классический кейс «а давайте лучше робота»: с ним не нужно будет дорабатывать информационные системы.
В качестве платформы роботизации был выбран UiPath: абсолютный лидер на рынке РФ и один из лидеров глобального рынка RPA, кроме того, уже обкатанный в головном офисе нашего партнера в Европе.
Чего мы хотели от робота?
У этой роботизации было несколько основных и вспомогательных целей. Основные цели были достаточно стандартные: процесс нужно было автоматизировать не менее чем на 90% (звучит впечатляюще, но для мира RPA это норма), сократив затраты на него по сравнению с ручным трудом. Второстепенные цели были любопытнее:
● выявить аномальные расхождения, которые человек может пропустить;
● снизить риск ошибки специалистов по товарному предложению;
● предотвратить расширение штата бухгалтеров при увеличении объемов поставок;
● ускорить проведение оплат поставщикам.
На основе всего этого мы поставили перед собой такие задачи:
● разработать роботов, которые будут выполнять работу бухгалтеров;
● разработать сервис их взаимодействия с бухгалтерами и СТП; не допускающий использования вил и факелов
● реализовать процесс извлечения данных из сканов бумажных документов;
● интегрировать роботов с системой распознавания бумажных документов.
Ну и как же без дополнительных требований от заказчика:
● runtime-лицензии роботов должны использоваться максимально эффективно. Лишние действия, задержки — все это должно быть сведено к минимуму;
● решение должно быть надежным и отказоустойчивым. При падениях, по словам заказчика, «роботы сами должны себя поднимать»!
● отсутствие у роботов дублирования функций;
● приоритизация срочных задач (например, отчетов);
● минимизация поддержки решения после ввода в эксплуатацию;
● автоматический онлайн-расчет окупаемости (дэшборд в Confluence);
● и еще, чтоб участников процесса письмами/уведомлениями не спамило.
Подход к проблеме и проект
С самого начала заказчику было ясно, что автоматизировать процесс на 100% невозможно, да и не нужно: не все бумажные документы нормально распознаются, не во всех бумагах будут артикулы для сопоставления с заказами ритейлера, поставщики наверняка будут допускать ошибки… Поэтому человека мы из процесса не исключали: он в любом случае должен был остаться в роли супервайзера, а также для решения нестандартных задач.
Итак, сформулировав процесс AS-IS, мы декомпозировали его на подпроцессы для роботизации. Получилось вот так:

На этом этапе было важно распределить задачи между подпроцессами и понять, что будет являться минимальной неделимой единицей обработки информации в роботизированной системе. Для нас ею стала приёмка заказа, по которой требовалось определить расхождение в стоимости. Каждую приёмку нужно было обрабатывать в контексте своего заказа, т.е. если в одном заказе несколько приёмок, они должны обрабатываться последовательно.
Однотипные задачи мы сразу стали собирать в совместную обработку, помня о требовании об эффективном расходовании runtime-лицензии. На практике это значило, что если нужно выгрузить из ЭХД 10 доков, то открывать его мы будем 1 раз, выгружать нужное и 1 раз закрывать, а не открывать и закрывать для каждого документа.
Архитектуру системы полностью определило решение формировать списки задач для каждого роботизируемого процесса в СУБД (MS SQL). Тем более что, как мы выяснили, отчёт из учетной системы (на базе СУБД ORACLE) можно выгружать запросом. Поэтому мы решили сделать Link к БД учетной системы и настроить Job в БД для регулярной выгрузки новых приемок, готовых к сопоставлению. Этот Job будет также анализировать полученные данные и переводить приемки на нужный этап обработки: «Требует согласования с СТП», «Требует выгрузки в систему распознавания», «Передать в оплату» и т.д.
Роботу оставалась только грязная работа по выполнению механических операций в соответствии с установленным статусом.
Что еще нужно было определить перед тем, как приступить к работе?
Архитектура распознания документов
Наш робоподопечный должен был уметь распознавать документы — такое «зрение» ему мы сделали на известной платформе ABBYY FlexiCapture. У нее есть, во-первых, готовые шаблоны распознавания для первичных документов (мы лишь немного докрутили их под примеры заказчика). Во-вторых, она предоставляет удобный интерфейс для верификации результатов распознавания, а это экономит время тому, кто верифицирует.
В этом процессе было несколько критически важных точек: качественное извлечение табличной части документа; проверка артикулов в БД (да, номенклатура также выгружалась из БД ERP-системы); сверка суммы документов; проверка совпадения штрихкода на документе и в ERP.
В общем виде процесс распознавания получился следующий:
1. Робот получает сразу все задачи по выгрузке бумажных документов из ЭХД. При этом в базе данных для каждого процесса подготовлена соответствующая вьюха, возвращающая список приемок и необходимые атрибуты для конкретного процесса.
2. Робот открывает ЭХД и начинает выгрузку сканированных образов бумажных документов в горячую папку ABBYY FlexiCapture. Для каждого документа формируется файл описания, чтобы система ABBYY понимала, о какой приемке идет речь, и могла корректно выполнять запросы к справочникам ERP.
3. Файл изображения попадает в систему распознавания, типизируется, из него извлекаются табличная часть, штрихкод и общая сумма документа. При этом совпадение штрихкода, наличие артикулов в БД, соответствие суммы всех цен на товары в таблице итоговой сумме документа гарантирует, что документ был распознан верно и ошибок тут быть не может. Значит, можно пропустить пользовательский этап верификации!
3.5. Если же ошибки присутствуют, то бухгалтеру ответственного за этот документ отдела приходит через e-mail напоминание о необходимости верифицировать документ. В приложении верификации видно документы с ошибками.
4. ABBYY FlexiCapture экспортирует проверенные данные в БД и устанавливает статус для соответствующих приемок «Готово к дальнейшей обработке».

Формирование интерфейса
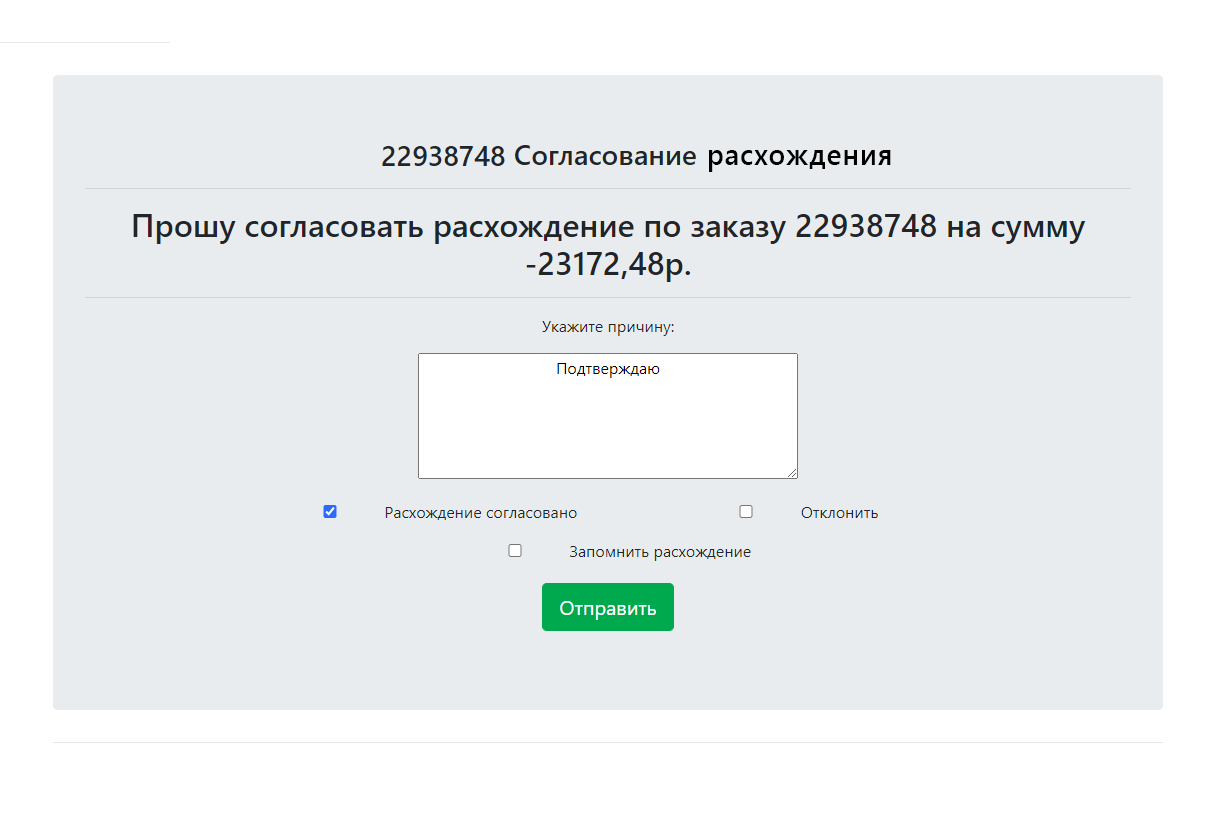
Для взаимодействия с пользователями изначально планировали использовать Jira, но затем мы приняли решение упростить интерфейс. Мы разработали собственный сервис по взаимодействию с пользователями. Если требуется согласовать расхождение, робот присылает сотруднику по товарному предложению ссылку в письме. При переходе по ней формируется web-страница, при этом проверяется, не был ли этот заказ уже согласован, а также имеет ли данный человек все необходимые права. На этой странице сотрудник выполняет согласование и вводит комментарий. После этого приемка в БД получает соответствующий статус для дальнейшей обработки роботом.
Что важно отслеживать в такой ситуации? Согласованные приемки, сотрудника, который их согласовал, а также его возможный комментарий. Но главное — обязательно нужно выполнить дополнительную проверку согласования бухгалтером (в компании уже был случай, когда СТП по ошибке согласовал очень крупное расхождение в цене).
Формирование отчетности
Важной частью работы стали отчеты. Все значимые действия роботов и сервиса взаимодействия с пользователями сохраняются в таблицу истории действий БД. Вместе с остальными хранящимися там данными это позволяет получить не только информацию для отчетов, но и выявить инциденты с ошибками.
Всего отчетов было реализовано четыре:
● отчет по задачам бухгалтеров (требуются ли действия от бухгалтера?);
● отчет главного бухгалтера (по задачам всех бухгалтеров);
● общий отчет по выявленным расхождениям;
● детальный отчет по расхождениям (с суммами по приёмкам и по поставщикам).
Каждый из них формируется на основе вьюхи из БД, в которой есть все необходимые данные. Роботу остается только сделать запрос, красиво и удобно его оформить — и предоставить пользователю на блюдечке с голубой каемочкой.
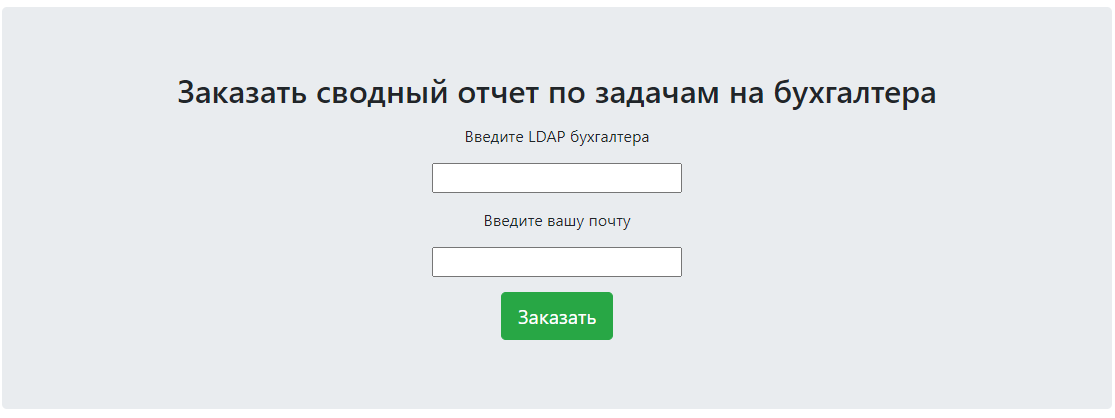
Пользователи должны были иметь возможность в любой момент получить необходимый им отчет, для чего было решено задействовать сервис взаимодействия с пользователями. Схема получилась такая: бухгалтеры на странице сервиса открывают форму заказа отчета с его параметрами (вроде периода, за который нужно сформировать отчет), заказ получает и исполняет робот.

Формирование графиков в Confluence
Помимо отчетов, робот также должен был строить real-time графики окупаемости самого себя. Для этого был разработан набор представлений в БД, в которых рассчитываются ключевые метрики робота. Методология расчета метрик включает в себя все затраты на роботизацию процесса, в том числе стоимость лицензий, серверов, стоимость наших услуг, а также зарплату бухгалтеров, ведь полностью мы их не исключили из процесса. Для отображения графика на странице в Confluence используется плагин Database Query.
С какими трудностями мы столкнулись
Если и бывают проекты, которые проходят без сучка и задоринки, то редко — и наша роботизация не стала исключением. В процессе мы столкнулись с несколькими затруднениями в реализации задуманного — и решили их.
Проблемы при заказе отчетов — как сделать так, чтобы робот выполнял приоритетные задачи раньше других?
После реализации персонализированных отчетов мы столкнулись с проблемой приоритизации задач.
Каждое утро бухгалтеры начинали с того, что заказывали у робота отчеты о проделанной работе. Именно утро — пиковый период работы: приемок очень много, все роботы заняты, отчеты встают в длинные очереди, пользователи ждут их очень долго, т.к. задание на формирование отчета добавлялось в общую очередь задач робота.
Для решения проблемы мы выделили срочные задачи в отдельную очередь и настроили робота на проверку наличия заданий в ней. Если такие возникают, обычные процессы останавливаются, и стартует срочный. Также было решено сделать робота-диспетчера (мы назвали его Доминатор), который запускался после каждого процесса и выбирал, какой процесс запустить следующим.
Таким образом, при наличии в очереди задач на формирование отчета, робот практически сразу брался за их выполнение.
Как заставить робота «самого себя поднимать»
С самого начала заказчик предупредил нас, что системы, с которыми предстояло работать роботу, нестабильны. Соответственно, ему предстояло качественно обрабатывать их ошибки.
Например, если учетная система падает во время исполнения роботом задачи, он должен через фиксированное время делать еще одну попытку. Если система остается недоступна несколько часов, робот должен писать заявку в поддержку этой системы в Jira.
В качестве основы всех процессов мы использовали Enhanced REFramework. Нас устраивали его расширенное логирование и централизованная обработка исключений.
Робот копил информацию о произошедших ошибках и выполнял соответствующие действия в зависимости от типа ошибки. В алгоритмы обработки ошибок были заложены попытки решить проблему локально, например, перезапустить текущую страницу в браузере. Если это не удавалось, то ошибка передавалась на централизованную обработку. Если ошибка повторялась 3 раза, то робот переходил к следующей приемке, а для этой устанавливался статус «Завершено с ошибкой» с отправкой уведомления администратору.
Переиспользование частоиспользуемых процессов (инвоуков)
Ввиду большого количества разрабатываемых процессов встает вопрос о переиспользовании повторяющихся разработок. Например, во все наши процессы входит взаимодействие с базой данных, во многие — получение и отправка писем, открытие и закрытие учетных систем. Все разработанные последовательности действий, которые могут быть переиспользованы, мы собрали в отдельные библиотеки и объединили в nuget-пакеты по области их применения. Пакеты хранятся в оркестраторе и GIT, соответственно, все разработчики имеют доступ к актуальной версии.
Кастомные активности
Не обошлось без разработки собственных активностей. Например, мы не нашли в публичном доступе активностей для группировки, условного форматирования, задания размера колонок и строк в Excel. Также не было функционала, чтобы отметить письмо как непрочитанное, и других возможностей при работе с почтой Exchange. Мы разработали как свои собственные активности с нуля, так и расширили возможности уже существующих в UiPath активностей. Далее мы упаковали их в библиотеки UiPath с некоторыми общими пространствами имен, например:
· работа с БД (получение данных по приемкам, по отчетам, сохранение статусов и т.д.);
· работа с почтой (получение запросов от бухгалтеров, отправка уведомлений);
· работа с Excel (форматирование, группировка, сортировка и т.д.);
· работа с учетными системами (авторизация, проверка ошибок).
Все это используется в разных роботизируемых процессах разными роботами и хранится в Оркестраторе, оставаясь доступным для всех разработчиков.
Курьезный случай — исчезновение штрихкодов
Одним прекрасным днем, когда мы уже практически праздновали победу, бухгалтеры подняли тревогу: из системы начали пропадать штрихкоды по документам, сверенным роботом. Проблема эта была критическая, из-за нее возник риск некорректной оплаты поставщикам: не тем, не те суммы, не по тем документам. В общем, робота остановили.
Этот случай очень показателен: многие думают, будто роботы могут сами принимать решения, совершать что-то незапрограммированное или даже сливать кому-нибудь на сторону конфиденциальную или коммерческую информацию. Конечно же, роботам это не интересно, и наши не исключение. Они работают по четким алгоритмам (скриптам), и любое отклонение просто невозможно, если только это не разработчик ошибся.
Мы как могли защищали наших роботов. Мы замедлили их работу, добавили сохранение скриншотов на ключевых этапах. Мы даже сниффили с помощью WireShark запросы, уходящие со страницы системы, в которой работал робот. Последнее доказало, что он выполнял свою работу корректно, это повысило уровень доверия заказчика и обеспечило их наикрутейшим алиби. Однако проблема так и осталась, а в логах учетной системы по-прежнему отражалась учетка робота как пользователя, который стирал штрихкоды.
Пришлось-таки подключить команду сопровождения этой учетной системы. Мы совместно настроили расширенную трассировку процесса и уже на первом же тестовом прогоне обнаружили место сбоя. Виновником был java-скрипт на стороне учетной системы. Коллеги выпустили патч — и проблема исчезла.
То есть нам не просто удалось отстоять своих ни в чем не повинных роботов, но даже помочь заказчику закрыть с их помощью критичный баг в учетной системе.
Результаты
Как мы говорили в самом начале, от нас требовалась оптимизация рабочего процесса на 90%. Как вычислить этот показатель? Для этого нужно сравнить время, которое будет потрачено на нужный процесс с роботом и без него. Мы определили, сколько занимали все составляющие роботизированной работы — выгрузка актов, работа в ABBYY, составление отчетов и даже написание писем; задали резерв на обслуживание робота.
И выяснили, что с задачами, на которые штат бухгалтеров ежедневно тратил время девяти полностью занятых профессионалов, робот справляется примерно за половину одного рабочего дня (0,47 рабочего дня, если быть точным). Точный показатель — 94% оптимизации. Это была победа!

Наш заказчик доволен, выбранный подход подтверждает свою эффективность. Дорабатывать учетные системы было бы дольше и дороже, а по результатам роботизации наш партнер принял решение по использованию RPA в других рутинных процессах.
В частности, прямо сейчас мы роботизируем для него два других процесса, в том числе обработку актов сверки поставщиков.
Спасибо всем дочитавшим до этого момента. Если у вас возникли вопросы, мы будем рады на них ответить!