Пора избавляться от мышки или Hand Pose Estimation на базе LiDAR за 30 минут

Всем привет! Пока киберпанк еще не настолько вошел в нашу жизнь, и нейроинтерфейсы далеки от идеала, первым этапом на пути к будущему манипуляторов могут стать LiDAR. Поэтому, чтобы не скучать на праздниках, я решил немного пофантазировать на тему средств управления компьютером и, предположительно, любым устройством, вплоть до экскаватора, космического коробля, дрона или кухонной плиты.
Предлагаю начать с посмотра коротенького видео, на котором видно, как можно за пару вечеров накидать простейшее управления курсором мышки на основе Object Detection, Hand Pose Estimation и камеры Intel Realsense L515. Конечно, оно далеко от идеала, но кажется, что осталось совсем немного подтянуть технологии и появятся принципиально новые способы управлять устройствами.
Справа на экране в реальном времени происходит отображение руки в RGB и Depth формате, то есть на карте глубины, получаемой с лидара, что даёт нам возможность получить координаты ключевых точек фаланги пальца — это красные и чёрные точки соотвественно. Как видно на видео, курсор двигается довольно плавно, и мне не потребовалось долго привыкать к такому управлению.
Зелёный луч, выходящий из указательного пальца — это проекция прямой, пересекающий плоскость монитора на ось XY. Спустя пару минут я уже мог направить палец-курсор в нужное мне место.
Основная идея — это двигать мышь, передвигая не всю руку, а только указательный палец, что позволит не отрывая рук от клавиатуры, бегать по меню, нажимать кнопки и в совокупности с горячими клавишами превратиться в настоящего клавиатурного ninja! А что будет если добавить жесты пролистывания или скоролла? Думаю будет бомба! Но до этого момента нам еще придётся подождать пару-тройку лет)
Начнём собирать наш протитип манипулятора будущего
Что понадобится:
1. Камера с LiDAR Intel Realsense L515.
2. Умение программировать на python
3. Совсем чуть-чуть вспомнить школьную математику
4. Крепление для камеры на монитор ака штатив
Крепим камеру на шатив с алиэкспресс, он оказался очень удобный, лёгкий и дешевый =)

Разбираемся, как и на чём делать прототип
Существует много подходов для реализации подобной задачи. Можно самому обучить детектор или сегментацию руки, вырезать полученное изображение правой руки и дальше применить к изображению вот этот замечательный репозтиторий от Facebook research, получить отличный результат или сделать еще проще.
Использовать mediapipe репозиторий, прочитав эту ссылку можно понять, что это один из лучших вариант на сегоднешний день.
Во-первых, там все уже есть из коробки — установка и запуск потребует минут 30, с учётом всех пререквизитов.
Во-вторых, благодаря мощной команде разработчиков, они не только бирут State Of Art в Hand Pose Estimation, но и дают лёгкое в понимание API.
В-третьих, сеть готова работать на CPU, так что порог входа минимален.
Наверное, вы спросите почему я не зашёл вот сюда и не воспользовался репозиториями победителей этого соревнования. На самом деле я довольно подробно изучил их решение, они вполне prod-ready, никаких стаков миллионов сеток и т.д. Но самая большая проблема, как мне кажется — это то, что они работают с изображением глубины. Так как это академики, они не гнушались все данные конвертировать через матлаб, кроме того, разрешение, в котором были отсняты глубины, мне показались маленьким. Это могло сильно сказаться на результате. Поэтому, кажется, что проще всего получить ключевые точки на RGB картинке и по XY координатам взять значение по оси Z в Depth Frame. Сейчас не стоит задача сильно что-то оптимизировать, так что сделаем так, как это быстрее с точки зрения разработки.
Вспоминаем школьную математику
Как я уже писал что бы получить координату точки, где должен оказаться курсор мышки, нам необходимо построить линию, проходящую через две ключевые точки фаланги пальца, и найти точку пересечения линии и плоскости монитора. 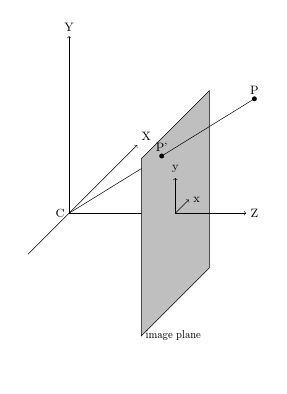
На картинке схематично изображена плоскость монитора и линия, ее пересекающая. Посмотреть на математику можно тут
По двум точкам получаем параметрическое представление прямой в пространстве.

Не буду сильно заострять внимание на школьной программе математики.
Установка бибилотеки для работы с камерой
Пожалуй, это самая сложная часть этой работы. Как оказалось, софт для камеры под Ubuntu очень сырой, librealsense просто завален все возможными багами, глюками и танцами с бубном.
До сих пор мне не удалось победить странное поведение камеры, иногда она не подгружает параметры при запуске.
Камера работает только один раз после рестарта компьютера!!! Но есть решение: перед каждым запуском делать програмно hard reset камеры, резет usb, и, может быть, всё будет хорошо. Кстати для Windows 10 там все нормально. Странно разработчики себе представляют роботов на базе винды =)
Чтобы под Ubuntu 20 у вас завелся realsense, сделайте так:
$ sudo apt-get install libusb-1.0-0-dev
Then rerun cmake and make install. Here is a complete recipe that worked for me:
$ sudo apt-get install libusb-1.0-0-dev
$ git clone https://github.com/IntelRealSense/librealsense.git
$ cd librealsense/
$ mkdir build && cd build
$ cmake ../ -DFORCE_RSUSB_BACKEND=true -DBUILD_PYTHON_BINDINGS=true -DCMAKE_BUILD_TYPE=release -DBUILD_EXAMPLES=true -DBUILD_GRAPHICAL_EXAMPLES=true
$ sudo make uninstall && make clean && make && sudo make installСобрав из сорцов, оно будет более или менее стабильно.
Месяц общения с техподдержкой выявил, что надо ставить Ubuntu 16 или страдать. Я выбрал сами понимаете что.
Продолжаем разбираться в тонкостях работы нейросети
Теперь посмотрим еще одно видео работы пальца-мышки. Обратите внимание, что указатель не может стоять на одном месте и как бы плавает вокруг предполагаемой точки. При этом я могу легко его направить к необходимому мне слову, а вот с буквой сложнее, приходится, аккуратно подводить курсор:
Это, как вы поняли, не тряска моих рук, на праздниках я выпил всего одну кружку New England DIPA =) Все дело в постоянных флуктациях ключевых точек и Z-координаты на основе значений, получаемых от лидара.
Посмотим вблизи:
В нашей SOTA от mediapipe флуктаций конечно меньше, но они тоже есть. Как выяснилось, они борются с этим путём прокидывания из прошлого кадра heatmap в текущий кадр и обучают сеть — это даёт больше стабильности, но не 100%.
Еще, как мне кажется, играет роль специфика разметки. Врядли можно сделать на таком колличестве кадров одинаковую разметку, не говоря уже о том, что разрешение кадра везде разное и не очень большое. Также мы не видим мерцание света, которое, вероятнеё всего, не постоянно из-за разного периода работы и величины экспозиции камеры. И еще сеть возращает бутерброд из heatmap, равный количеству ключевых точек на экране, размер этого тензора BxNx96x96, где N — это кол-во ключевых точек, и, конечно же, после threshold и resize к оригинальному размеру кадра, мы получаем то что получаем =(
Прмер визуализации heatmap: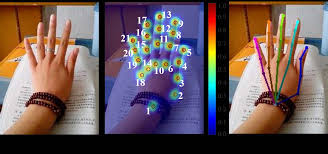
Обзор кода
Весь код находится в этом репозитории и он очень короткий. Давайте разберём основной файл, а остальное вы посмотрите сами.
import cv2
import mediapipe as mp
import numpy as np
import pyautogui
import pyrealsense2.pyrealsense2 as rs
from google.protobuf.json_format import MessageToDict
from mediapipe.python.solutions.drawing_utils import _normalized_to_pixel_coordinates
from pynput import keyboard
from utils.common import get_filtered_values, draw_cam_out, get_right_index
from utils.hard_reset import hardware_reset
from utils.set_options import set_short_range
pyautogui.FAILSAFE = False
mp_drawing = mp.solutions.drawing_utils
mp_hands = mp.solutions.hands
# инициализируем mediapipe для Hand Pose Estimation
hands = mp_hands.Hands(max_num_hands=2, min_detection_confidence=0.9)
def on_press(key):
if key == keyboard.Key.ctrl:
pyautogui.leftClick()
if key == keyboard.Key.alt:
pyautogui.rightClick()
def get_color_depth(pipeline, align, colorizer):
frames = pipeline.wait_for_frames(timeout_ms=15000) # ождидаем фрейм от камеры
aligned_frames = align.process(frames)
depth_frame = aligned_frames.get_depth_frame()
color_frame = aligned_frames.get_color_frame()
if not depth_frame or not color_frame:
return None, None, None
depth_image = np.asanyarray(depth_frame.get_data())
depth_color_image = np.asanyarray(colorizer.colorize(depth_frame).get_data())
color_image = np.asanyarray(color_frame.get_data())
depth_color_image = cv2.cvtColor(cv2.flip(cv2.flip(depth_color_image, 1), 0), cv2.COLOR_BGR2RGB)
color_image = cv2.cvtColor(cv2.flip(cv2.flip(color_image, 1), 0), cv2.COLOR_BGR2RGB)
depth_image = np.flipud(np.fliplr(depth_image))
depth_color_image = cv2.resize(depth_color_image, (1280 * 2, 720 * 2))
color_image = cv2.resize(color_image, (1280 * 2, 720 * 2))
depth_image = cv2.resize(depth_image, (1280 * 2, 720 * 2))
return color_image, depth_color_image, depth_image
def get_right_hand_coords(color_image, depth_color_image):
color_image.flags.writeable = False
results = hands.process(color_image)
color_image.flags.writeable = True
color_image = cv2.cvtColor(color_image, cv2.COLOR_RGB2BGR)
handedness_dict = []
idx_to_coordinates = {}
xy0, xy1 = None, None
if results.multi_hand_landmarks:
for idx, hand_handedness in enumerate(results.multi_handedness):
handedness_dict.append(MessageToDict(hand_handedness))
right_hand_index = get_right_index(handedness_dict)
if right_hand_index != -1:
for i, landmark_list in enumerate(results.multi_hand_landmarks):
if i == right_hand_index:
image_rows, image_cols, _ = color_image.shape
for idx, landmark in enumerate(landmark_list.landmark):
landmark_px = _normalized_to_pixel_coordinates(landmark.x, landmark.y,
image_cols, image_rows)
if landmark_px:
idx_to_coordinates[idx] = landmark_px
for i, landmark_px in enumerate(idx_to_coordinates.values()):
if i == 5:
xy0 = landmark_px
if i == 7:
xy1 = landmark_px
break
return color_image, depth_color_image, xy0, xy1, idx_to_coordinates
def start():
pipeline = rs.pipeline() # инициализируем librealsense
config = rs.config()
print("Start load conf")
config.enable_stream(rs.stream.depth, 1024, 768, rs.format.z16, 30)
config.enable_stream(rs.stream.color, 1280, 720, rs.format.bgr8, 30)
profile = pipeline.start(config)
depth_sensor = profile.get_device().first_depth_sensor()
set_short_range(depth_sensor) # загружаем параметры для работы на маленьком расстоянии
colorizer = rs.colorizer()
print("Conf loaded")
align_to = rs.stream.color
align = rs.align(align_to) # совокупляем карту глубины и цветную картинку
try:
while True:
color_image, depth_color_image, depth_image = get_color_depth(pipeline, align, colorizer)
if color_image is None and color_image is None and color_image is None:
continue
color_image, depth_color_image, xy0, xy1, idx_to_coordinates = get_right_hand_coords(color_image,
depth_color_image)
if xy0 is not None or xy1 is not None:
z_val_f, z_val_s, m_xy, c_xy, xy0_f, xy1_f, x, y, z = get_filtered_values(depth_image, xy0, xy1)
pyautogui.moveTo(int(x), int(3500 - z)) # 3500 хард код специфичый для моего монитора
if draw_cam_out(color_image, depth_color_image, xy0_f, xy1_f, c_xy, m_xy):
break
finally:
hands.close()
pipeline.stop()
hardware_reset() # делаем ребут камеры и ожидаем её появления
listener = keyboard.Listener(on_press=on_press) # устанавливаем слушатель нажатия кнопок клавиатуры
listener.start()
start() # запуск программы
Я не стал использовать классы или потоки, потому что для такого простого случая достаточно всё выполнять в основном потоке в бесконечном цикле while.
В самом начале происходит инициализация mediapipe, камеры, загрузка настроек камеры для работы short range и вспомогательных переменных. Следом идёт магия под названием «alight depth to color» — эта функция ставит в соответсвие каждой точки из RGB картинки, точку на Depth Frame, то есть даёт нам возможность получать по координатам XY, значение Z.
Понято что необходимо произвести калибровку на вашем мониторе. Я специально не стал вытаскивать отдельно эти параметры, что бы читатель решивший запустить код сделал это сам, за одно резберётся в коде =)
Далее мы берём из всего предсказания только точки под номером 5 и 7 правой руки.
Осталось дело за малым — полученные координаты фильтруем с помощью скользящего среднего. Можно было конечно применить более серьзные алгоритмы фильтрации, но взглянув на их визуализацию и подёргав разные рычажки, стало понятно, что для демо вполне хватит и скользящего среднего с глубиной 5 фреймов, хочу заметить что для XY вполне хватало и 2-3-х, но вот с Z дела обстоят хуже.
deque_l = 5
x0_d = collections.deque(deque_l * [0.], deque_l)
y0_d = collections.deque(deque_l * [0.], deque_l)
x1_d = collections.deque(deque_l * [0.], deque_l)
y1_d = collections.deque(deque_l * [0.], deque_l)
z_val_f_d = collections.deque(deque_l * [0.], deque_l)
z_val_s_d = collections.deque(deque_l * [0.], deque_l)
m_xy_d = collections.deque(deque_l * [0.], deque_l)
c_xy_d = collections.deque(deque_l * [0.], deque_l)
x_d = collections.deque(deque_l * [0.], deque_l)
y_d = collections.deque(deque_l * [0.], deque_l)
z_d = collections.deque(deque_l * [0.], deque_l)
def get_filtered_values(depth_image, xy0, xy1):
global x0_d, y0_d, x1_d, y1_d, m_xy_d, c_xy_d, z_val_f_d, z_val_s_d, x_d, y_d, z_d
x0_d.append(float(xy0[1]))
x0_f = round(mean(x0_d))
y0_d.append(float(xy0[0]))
y0_f = round(mean(y0_d))
x1_d.append(float(xy1[1]))
x1_f = round(mean(x1_d))
y1_d.append(float(xy1[0]))
y1_f = round(mean(y1_d))
z_val_f = get_area_mean_z_val(depth_image, x0_f, y0_f)
z_val_f_d.append(float(z_val_f))
z_val_f = mean(z_val_f_d)
z_val_s = get_area_mean_z_val(depth_image, x1_f, y1_f)
z_val_s_d.append(float(z_val_s))
z_val_s = mean(z_val_s_d)
points = [(y0_f, x0_f), (y1_f, x1_f)]
x_coords, y_coords = zip(*points)
A = np.vstack([x_coords, np.ones(len(x_coords))]).T
m, c = lstsq(A, y_coords)[0]
m_xy_d.append(float(m))
m_xy = mean(m_xy_d)
c_xy_d.append(float(c))
c_xy = mean(c_xy_d)
a0, a1, a2, a3 = equation_plane()
x, y, z = line_plane_intersection(y0_f, x0_f, z_val_s, y1_f, x1_f, z_val_f, a0, a1, a2, a3)
x_d.append(float(x))
x = round(mean(x_d))
y_d.append(float(y))
y = round(mean(y_d))
z_d.append(float(z))
z = round(mean(z_d))
return z_val_f, z_val_s, m_xy, c_xy, (y0_f, x0_f), (y1_f, x1_f), x, y, z
Создаем deque c длинной 5 фреймов и усредняем все подряд =) Дополнительно расчитываем y = mx+c, Ax+By+Cz+d=0, уравнение для прямой — луч на RGB картинке и уравнение плоскости монитора, оно у нас получается y=0.
Итоги
Ну вот и всё, мы запилили простейший манипулятор, который даже при своем драматически простом исполнении уже сейчас может быть, хоть и с трудом, но использован в реальной жизни!
Благодарности
Спасибо сообществу ods.ai, без него невозможно развиваться!