Привет, Хабр! Меня зовут Артемий Козырь.
За последние годы у меня накопился довольно обширный опыт работы с данными и тем, что сейчас называют Big Data.
Не так давно также разгорелся интерес к сфере интернет-маркетинга и Сквозной Аналитики, и не на пустом месте. Мой друг из действующего агентства снабдил меня данными и кейсами реальных клиентов, и тут засквозило понеслось.
Получается довольно интересно: Azure SQL + dbt + Github Actions + Metabase.
Итак, постараемся без дифирамб и сразу к делу. Портрет Клиента (это тот, для кого мы делаем сервис): владелец интернет-магазина / розничной сети / мобильного приложения / образовательной платформы. Он преследует следующие цели:
В среднем он пользуется 4-мя группами сервисов:
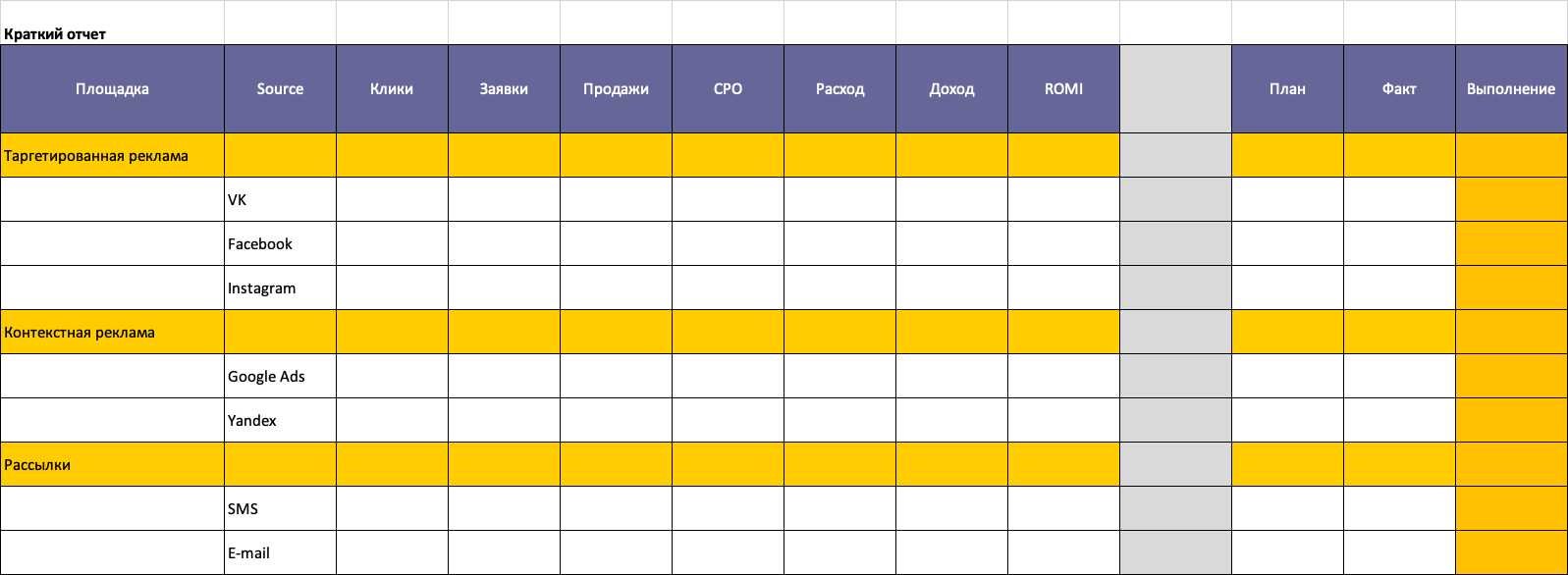
На помощь Клиенту приходит Агентство, которое оказывает комплексные услуги: разработка стратегии, создание креативов, настройка счетчиков и CRM, закупка рекламы. С Клиентом согласовывается объем работ и целевые показатели. Выглядеть это может примерно так:
Согласованная форма отчетности Агентства перед Клиентом
Самой интересной и сложной частью, на мой взгляд, является формирование сводной отчетности по результатам деятельности. С инженерной точки зрения задача сводится к следующему:
Даже ниндзя-одиночке сложно собрать и поддерживать набор коннекторов в актуальном и работоспособном состоянии. Ранее я выступал с небольшим докладом на эту тему: Сквозная аналитика: коробочные решения или самостоятельная сборка? (с 3:13).
Для своего решения я выбрал сервис myBI Connect. Алексей и его команда делают по-настоящему качественный сервис, который в состоянии удовлетворить даже самые изощренные требования инженеров и бизнес-пользователей. Давайте взглянем, что доступно из коробки:
1. Базовые выгрузки и модель детального слоя
Заботливо подготовлены и задокументированы модели детального слоя (те самые звездочки и снежинки), суррогатные ключи, метаданные обновлений и ETL-джобов.
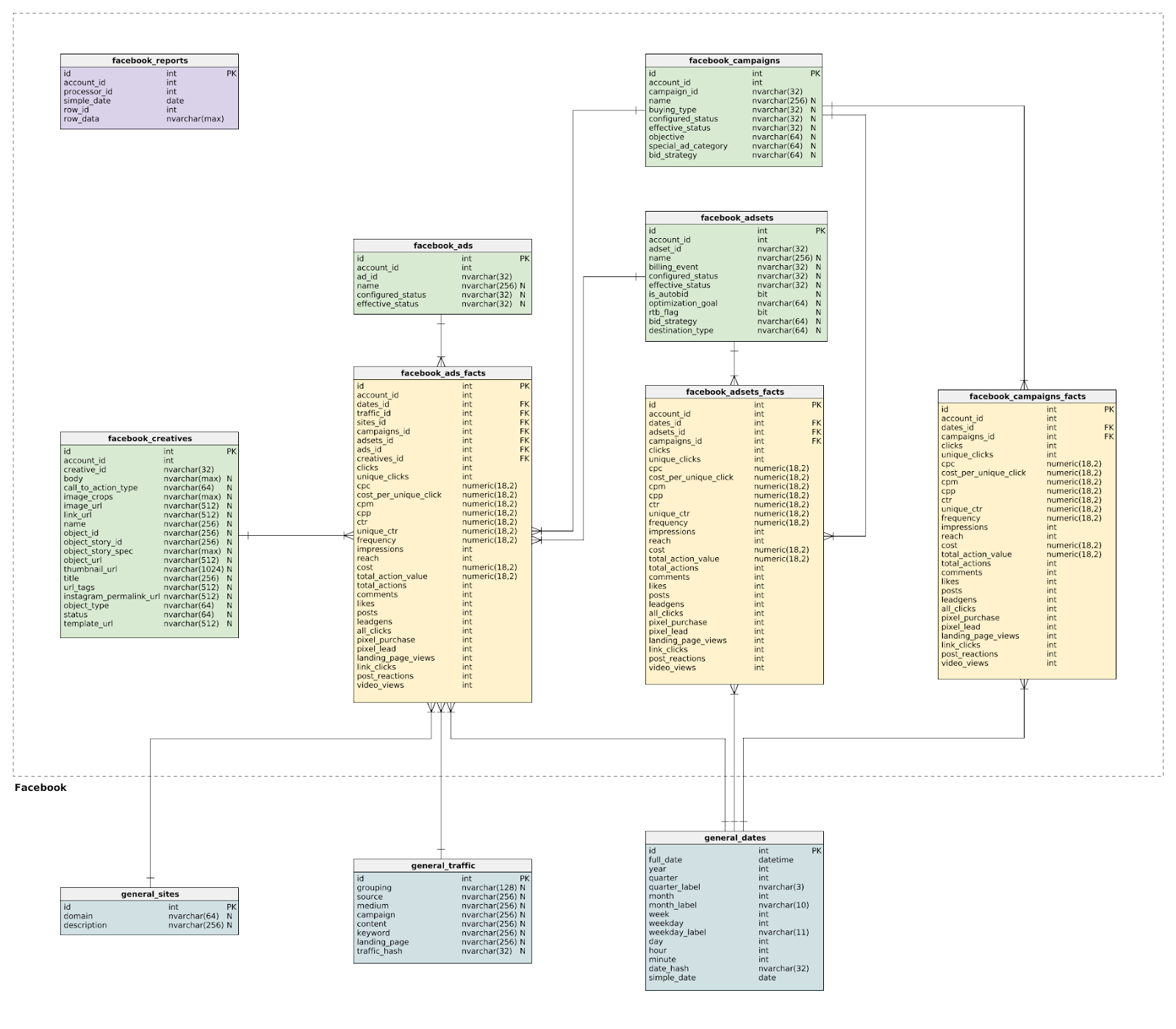
Например, для Facebook доступны уровни детализации Кампаний (Campaigns), Групп Объявлений (Adsets) и Объявлений (Ads), включая невероятный набор метрик, таких как среднее количество просмотров на человека, охват, реакции на публикации, репосты и т.д.
Схема детального слоя Facebook myBI Connect
2. Кастомизированные отчеты/выгрузки/представления
Все работали с Яндекс.Метрикой? По сути это конструктор отчетов с ныне очень известным Яндекс.Clickhouse под капотом. Чтобы собрать отчет, необходимо выбрать ряд Измерений, Метрик, Фильтров (образующих Сегменты).
https://api-metrika.yandex.net/stat/v1/data.csv
?ids=55254416
&dimensions=ym:s:date, ym:s:UTMSource, ym:s:UTMMedium, ym:s:UTMCampaign
&metrics=ym:s:visits, ym:s:ecommercePurchases, ym:s:ecommerceRevenue
&date1=2020-12-01
&date2=2020-12-31
&group=day
&lang=en
&accuracy=full
&sort=ym:s:date
&limit=100000
&pretty=trueА теперь вспомните о трансформации полученного в ответ JSON-документа, регулярность выгрузок (установка на расписание или cron), обработку статусов запросов (requests), удаление дубликатов и т.д. Не хотелось бы отягощать свое решение поддержкой всего этого.
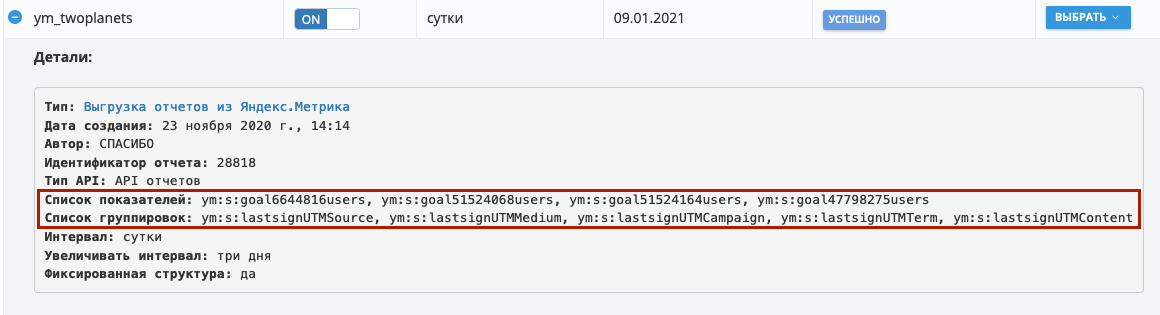
С использованием myBI Connect я один раз декларативно задаю структуру результирующего набора данных и регулярно получаю свежую выгрузку в реляционную СУБД без всякой головной боли.
Пользовательская выгрузка из Яндекс.Метрика
3. Webhook для данных, к которым пока нет коннектора
И такие данные тоже можно довольно легко собирать. Так может выглядеть скрипт получения конверсий из inhouse-CRM, отдающей данные в формате XML:
# get data from XML endpoint with curl utility
curl "https://www.internal-crm.ru/order-list.xml?date-from=01-12-2020&date-to=31-12-2020" -o export.xml
# convert XML to JSON with xq utility
xq . export.xml > export.json
# parse JSON doc with jq utility
jq '[."order-list".date[] | .order[]]' export.json > parsed.json
# post to myBI Connect Webhook endpoint with curl utility
curl --header "Content-Type: application/json"
--request POST
--data @parsed.json
https://app.mybi.ru/webhook/23576/xhsfcxmlyh/В примере получаем выгрузку данных в формате XML, преобразуем в JSON, парсим данные, отсылаем структурированный набор в myBI Connect через Webhook. Один несложный shell-скрипт, и данные почти мгновенно оказываются в таблице с конверсиями в Хранилище.
4. Приятные дополнительные возможности
В итоге я имею исходные наборы данных в понятном и ожидаемом формате, с регулярным обновлением. И это основа решения.
В значительной мере работа над Хранилищем Данных заключается в Моделировании данных (Data Modeling), или построении логической модели. Формально это означает преобразование, обогащение, сведение разрозненных наборов данных с целью получить интересующий набор показателей (метрик) с соблюдением бизнес-правил и логики расчетов.
Основные блоки DWH: источники, детальный слой, витрины данных
Концептуально DWH можно разделить на ряд областей:
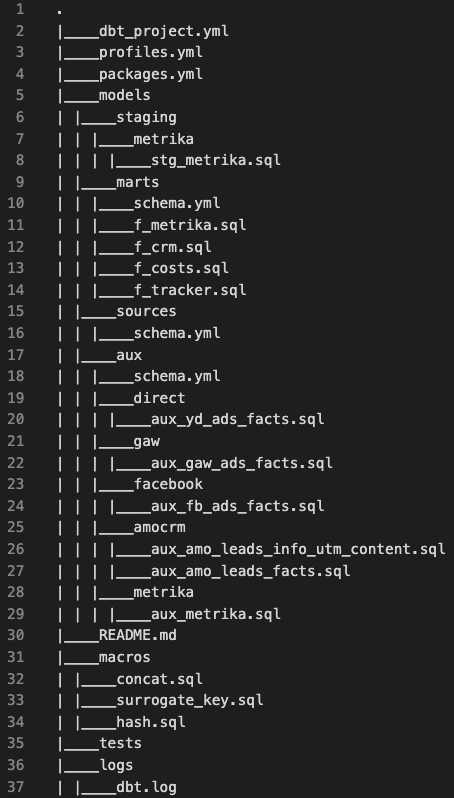
Для формирования логической модели я воспользовался dbt. В моем случае Хранилище Данных представляет из себя git-репозиторий, состоящий из набора файлов .sql (код витрин) и .yaml (конфигурация). На Хабре есть хороший обзор dbt на русском языке: Data Build Tool или что общего между Хранилищем Данных и Смузи.
В роли движка-СУБД может выступать любая из популярных сегодня аналитических баз данных: BigQuery, Redshift, Snowflake, Postgres, Spark, Presto. В моем случае это Azure SQL Database (managed SQL Server). По сути для меня не имеет значения, на какой инфраструктуре строить Хранилище; важна смысловая составляющая проекта, бизнес-логика, алгоритмы (читай код).
Структура проекта: git-репо с кодом (.sql) и конфигурацией (.yaml)
Для последовательности и структурированности я делю DWH на ряд слоев:
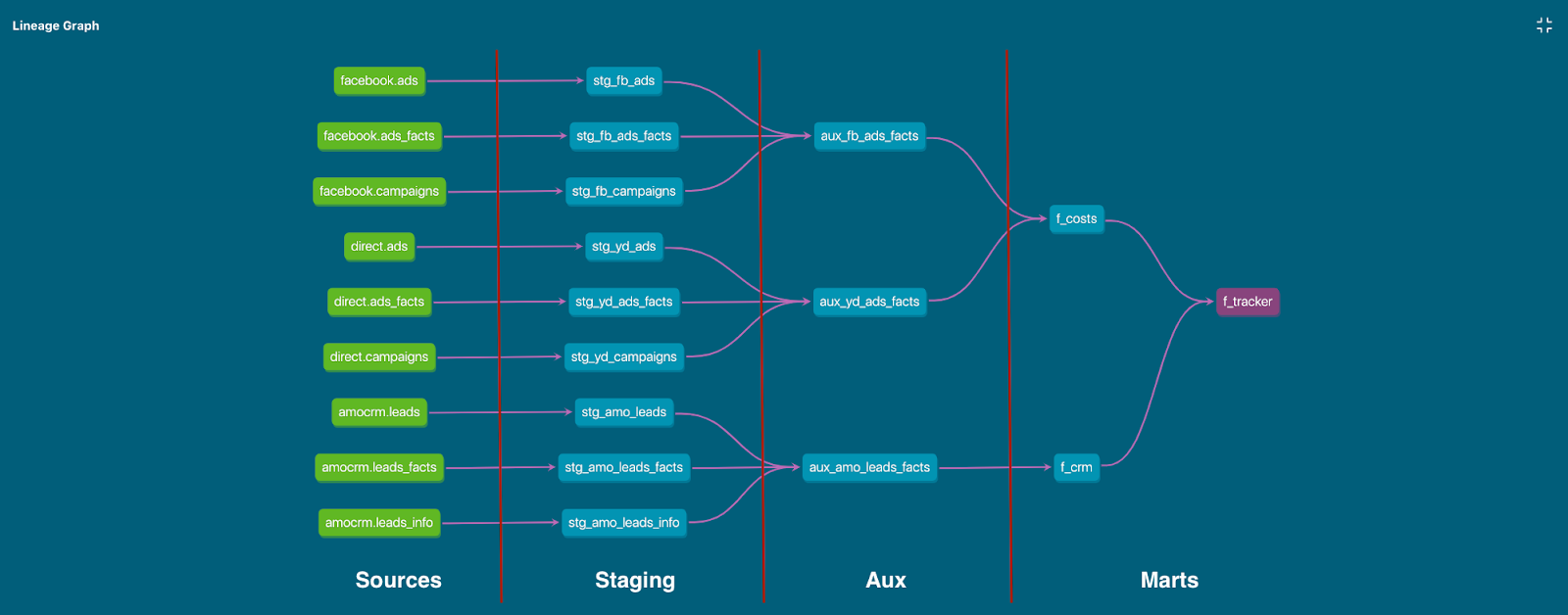
Цепочка зависимостей моделей: Источники -> Стейдж -> Вспомогательные -> Витрины
1. Источники (Sources)
По сути это ссылки-указатели на таблицы, которые регулярно обновляются сервисом myBI Connect. Для моего решения это исходные данные.
2. Стейдж (Staging)
Чаще всего модели стейджинга это виртуальные таблицы (представления или views), однако иногда я материализую их в виде физических таблиц для ускорения доступа. На этом этапе я:
3. Вспомогательный (Auxiliary)
Модели слоя Aux предназначены для формирования срезов по отдельным предметным областям. Здесь появляются первые денормализованные (широкие) аналитические таблицы:
4. Витрины (Marts)
Витрины данных — это то, на что смотрит конечный пользователь. Это семантический слой доступа, прослойка между бизнес-атрибутами и алгоритмами их формирования. Здесь я расположил максимально прилизанные и корректные данные. Именно здесь фокусируется внимание и интерес пользователей:
— Что кроме дашборда можно показать клиенту?
— Правильно, почти ничего.
Поэтому с точки зрения клиента визуальная подача результатов — это самое основное. И неважно, сколько времени вы потратили на выгрузку по API, отладку функций и макросов, или создание Github Action, который регулярно обновляет витрины.
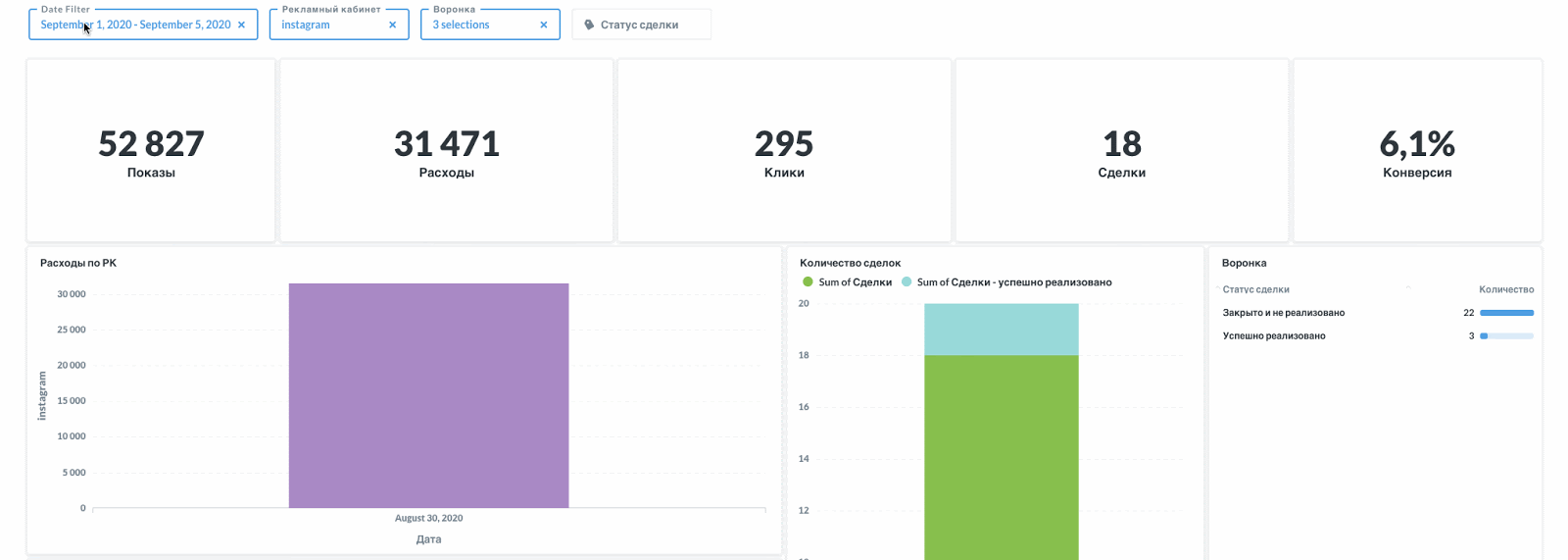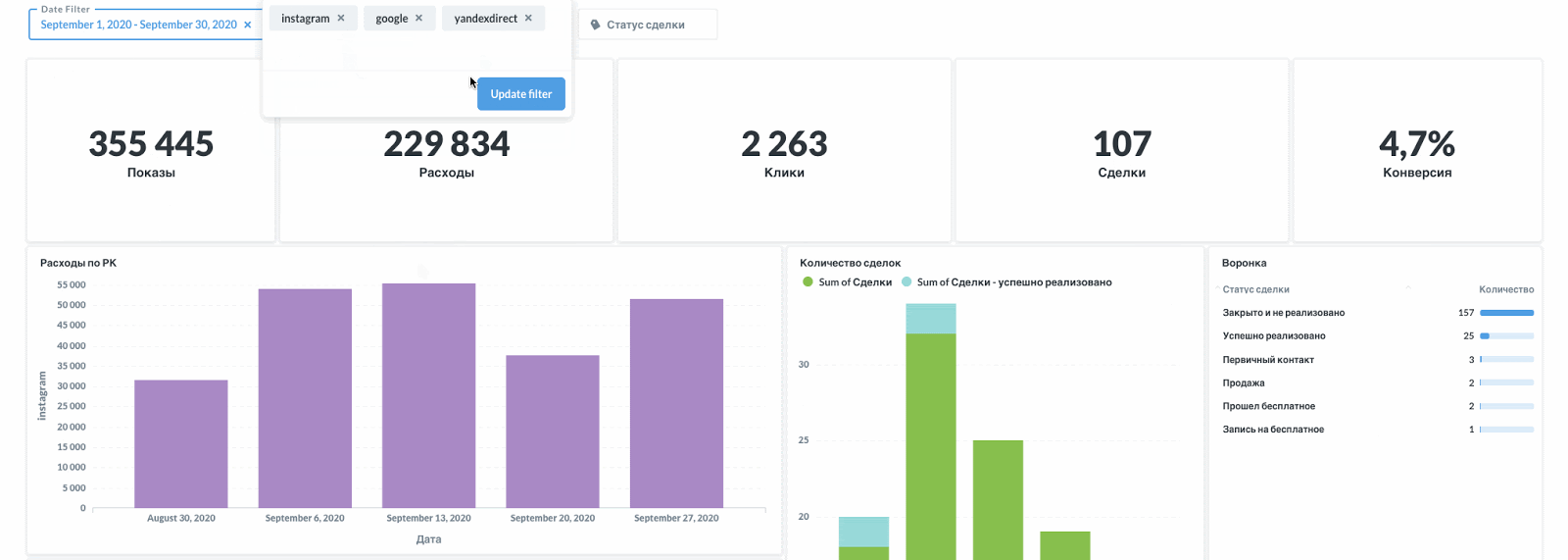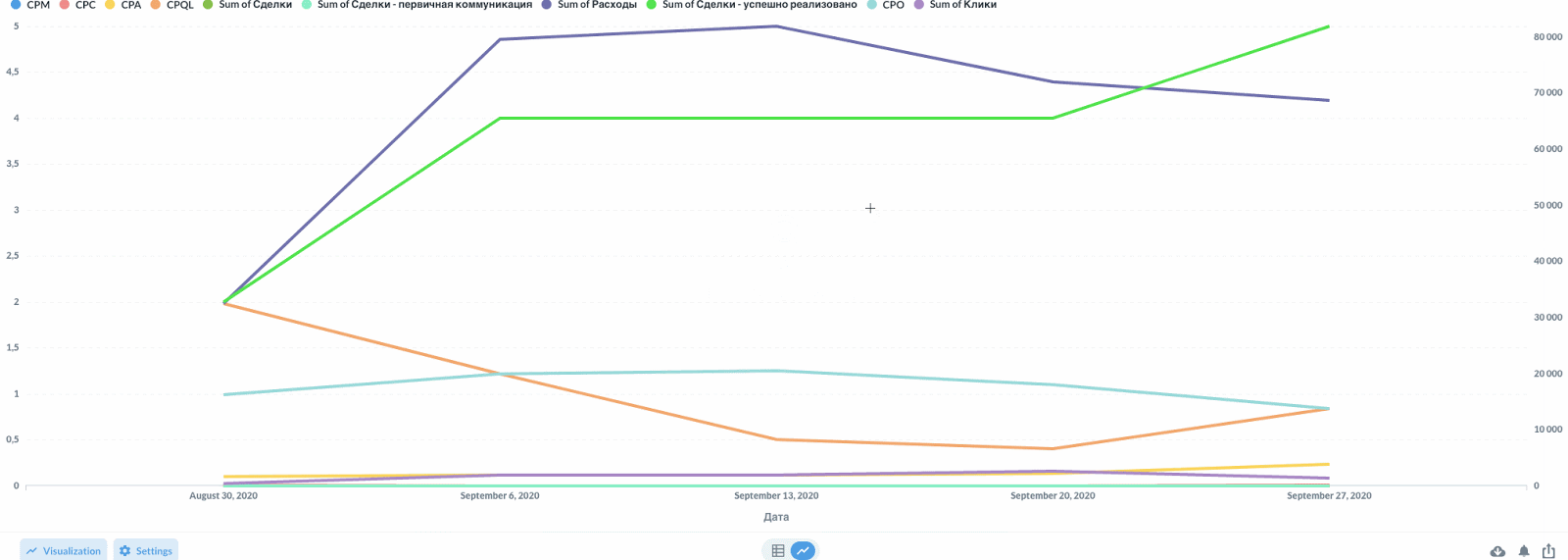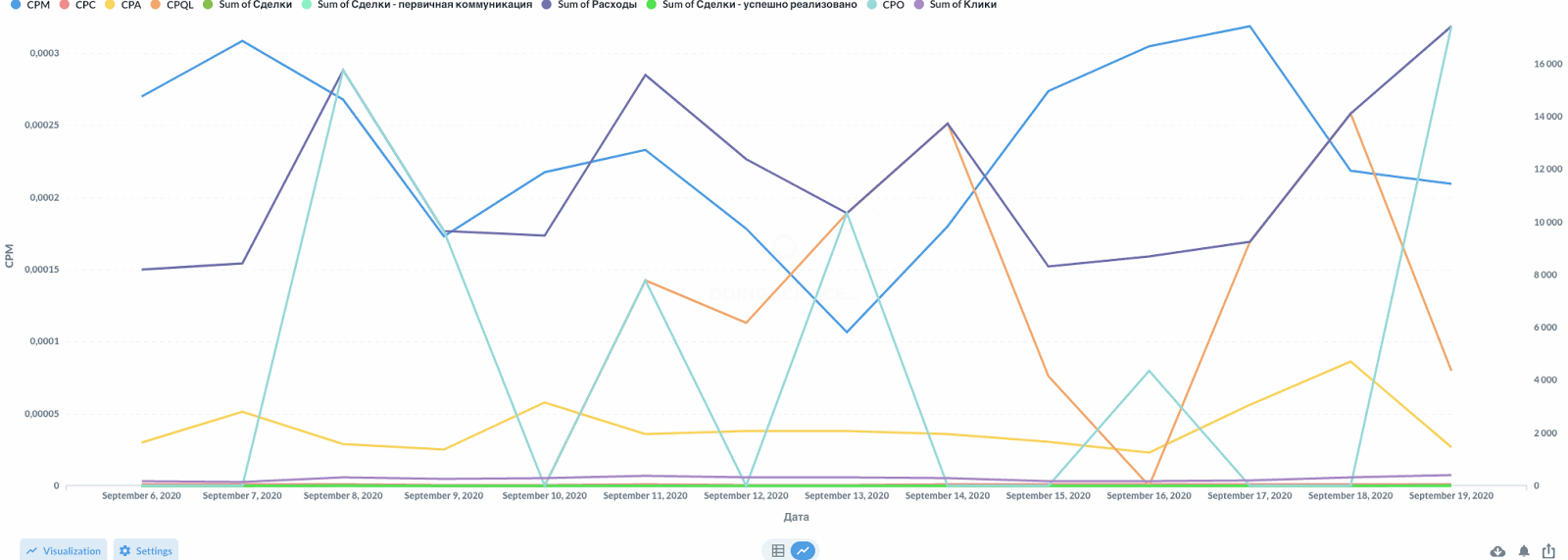
Визуализация динамики основных показателей на интерактивном дашборде
Дашборд это ни в коем случае не статический элемент. Здесь важен интерактив и динамика. Это портал к данным, откуда можно прыгнуть в детализацию или сфокусироваться на части данных (сегменты).
Приложение доступно как с компьютера, так и с мобильных устройств, планшетов. Дашборд можно спрятать за окно логина, им можно делиться публично с доступом по ссылке. Снимок дашборда можно регулярно получать по почте или в Slack.
Представленный дашборд — это моя разработка. Но у заинтересованного пользователя есть все инструменты, чтобы самостоятельно изучить доступные данные. Задать вопросы и собрать полученные ответы в собственные дашборды.
Семантический слой доступа к метаданным витрин и детального слоя
В удобном интерфейсе все метаданные как на ладони:
Работу всей этой красоты обеспечивает Open Source BI решение Metabase (рекомендую!). Я разместил его на Amazon Elastic Beanstalk, и это уже полноценное продуктивное развертывание:
Продуктивное развертывание BI Metabase в облаке AWS Elastic Beanstalk
Неужели всё так просто? Конечно нет! Если к текущему моменту сложилось ощущение, что всё выстраивается гладко и бесшовно, то это большое заблуждение. Ниже я системно опишу те болевые точки, с которыми столкнулся.
1. Кривая разметка и парсинг идентификаторов
Вся Сквозная Аналитика строится вокруг идентификаторов, по которым можно сопоставить данные из различных источников. Потому она и сквозная, т.е. проходящая сквозь
пространство и времясервисы и учетные системы.
Это ключевая фишка. Нет идентификаторов-якорей — нет сквозной аналитики. Важно следовать лучшим практикам и быть консистентным при запусках Кампаний во всех Рекламных Кабинетах.
(1) Легко допустить ошибку: поставить лишний символ, например, {фигурные скобки}, забыть указать UTM-метки (или указать дважды!), теги, ключевые слова. После запуска, к сожалению, это восстановлению уже не подлежит. Здесь наши полномочия всё, окончены.
(2) В другом случае мы теряли метки при обработке редиректа на веб-сервере. Веб-разработчик установил какой-то хитрый php-скрипт, назначение которого осталось для меня тайной.
(3) В третьих, это особенности разметки конкретных кабинетов. Я эмпирически выяснил, что Google Adwords к числовому идентификатору может подставлять буквенный префикс типа aud-, kwd-, pla-.
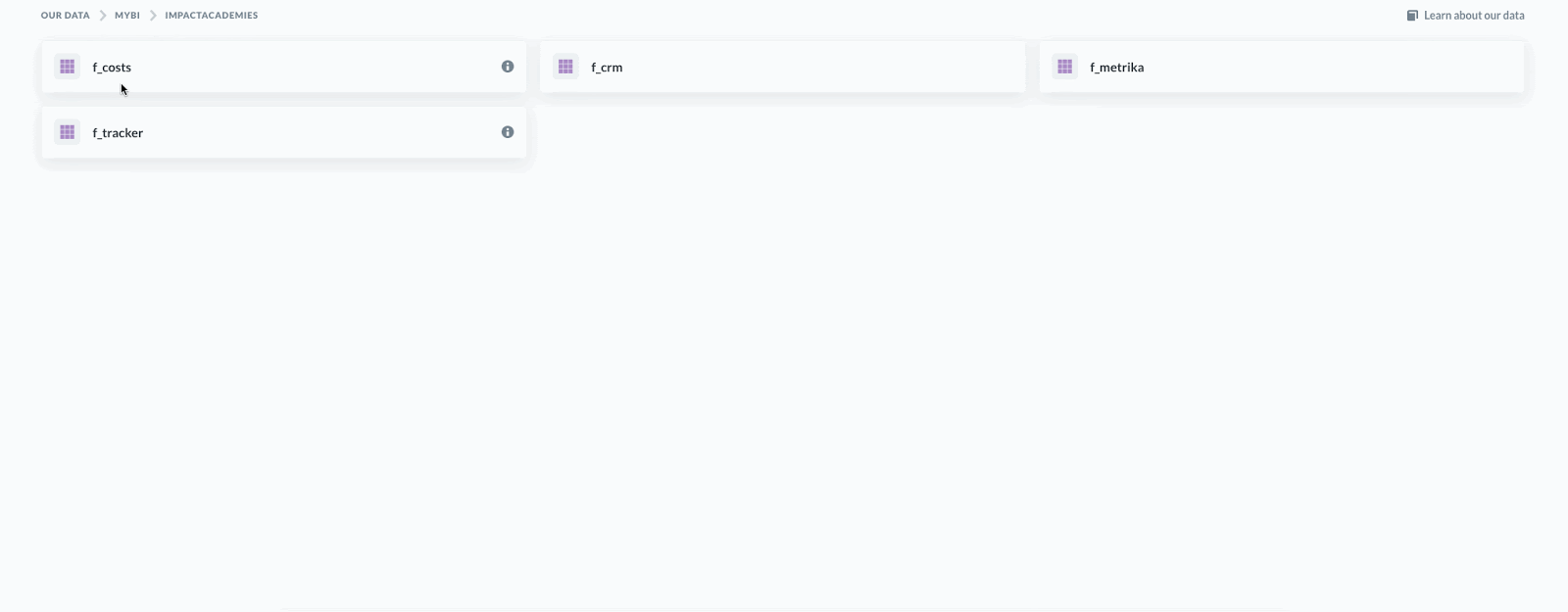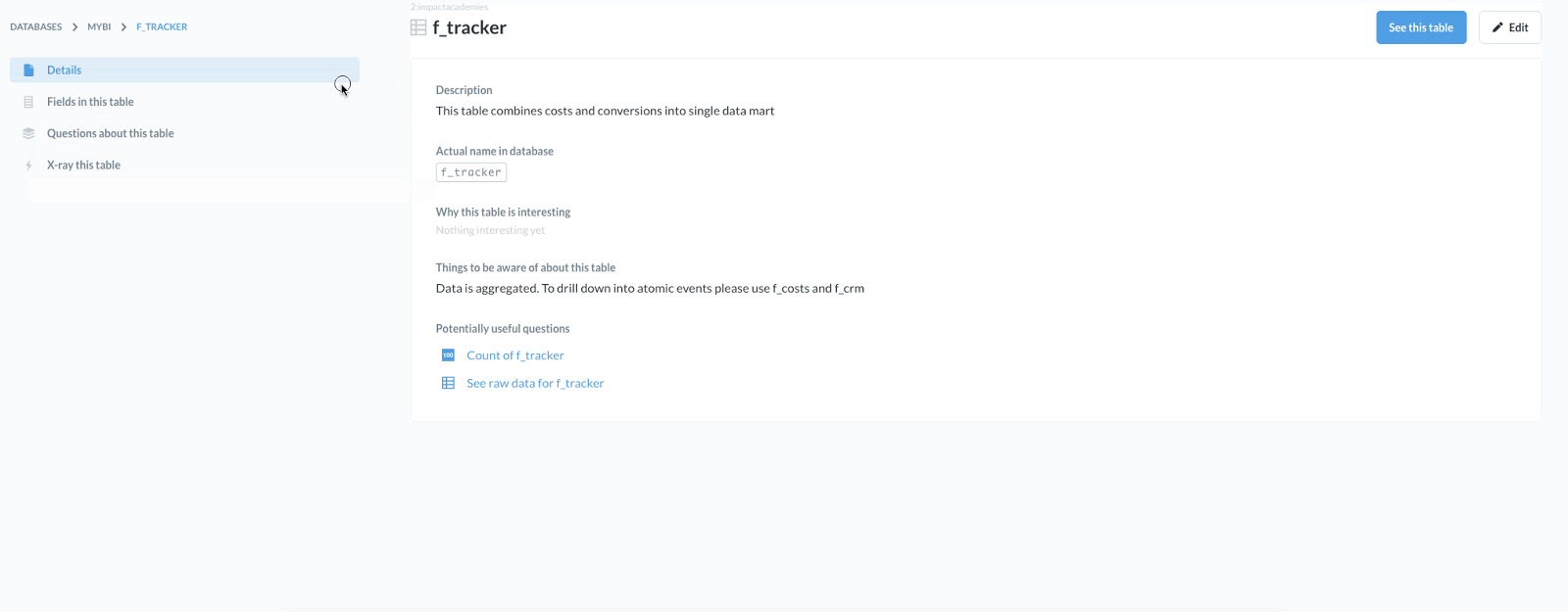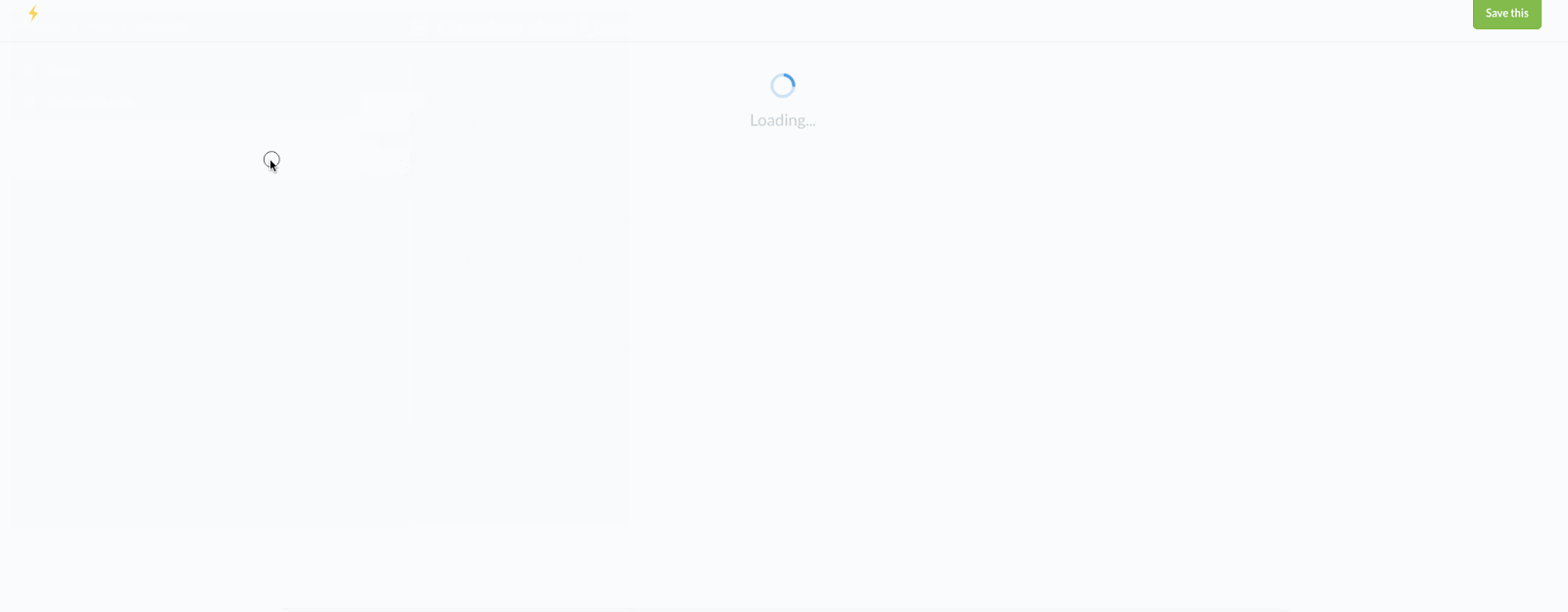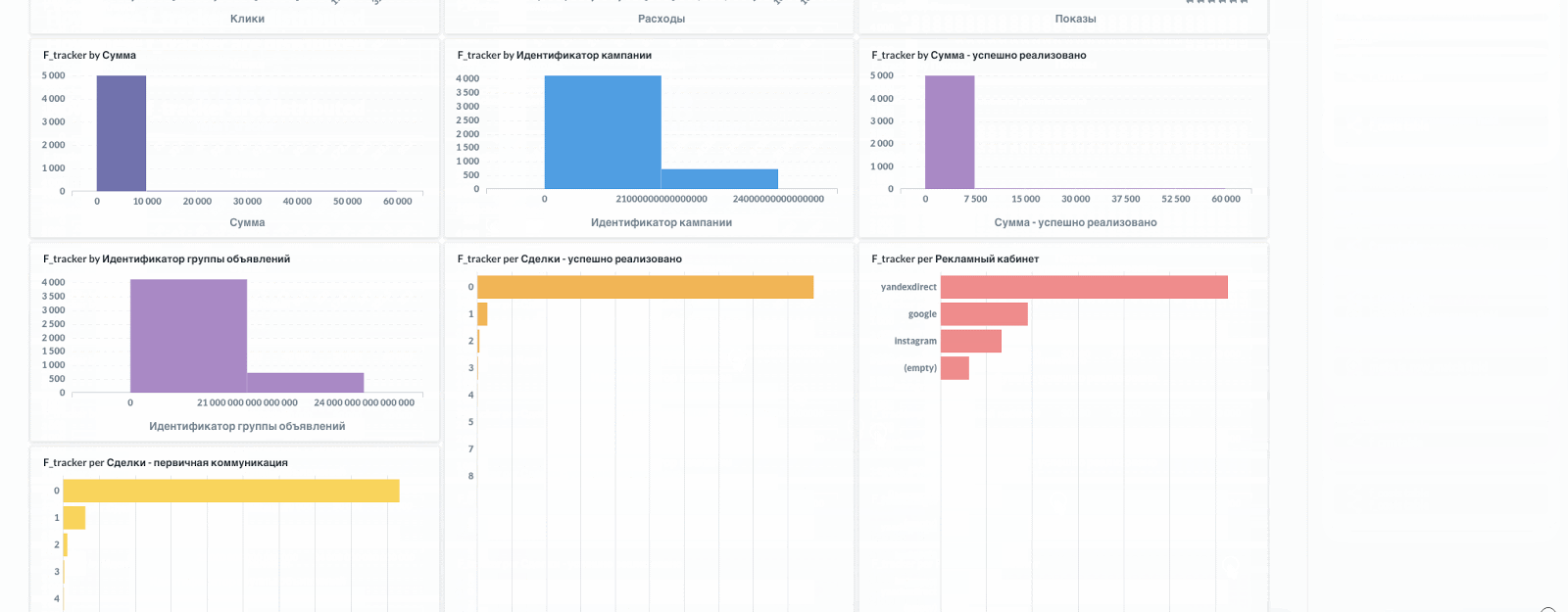
(4) Хорошая разметка, для примера. В ходе парсинга удалось достать все идентификаторы!
Примеры учета особенностей разметки для последующего парсинга идентификаторов
Все эти и другие скрытые особенности необходимо неустанно контролировать и учитывать в алгоритмах парсинга, чтобы получать качественные результаты.
2. Хаотичный учет сделок и воронок в CRM
В большей части выгрузок из CRM, с которыми я работал, налицо отсутствие системного подхода. Это означает стихийное заполнение статусов сделок, их параметров, принадлежность к воронкам и каналам-источникам лидов. Я вовсе не придираюсь, ведь всё дело в том, что и аналитика будучи приемником данных приобретает те же черты.
— Нет желания поддерживать актуальность, полноту и достоверность в CRM-системе, но при этом хочется иметь красивый результат в отчетах?
— Запомните: это так не работает.
Каков мой ответ? Я вывел на дашборд таблицу со сделками, в которых с разметкой не всё в порядке.
Проверочный дашборд по проблемным сделкам в CRM
3. Правила матчинга (поиск совпадений) и суррогатные ключи
Хорошо, предположим, что метки есть. Давайте склеивать данные. Решение в лоб: сделать джоин таблиц с условием совпадения всех полей. Выглядит как-то так:
from costs c
full join conversions cv on
c.[Дата] = cv.[Дата]
and c.[Идентификатор кампании] = cv.[Идентификатор кампании]
and c.[Идентификатор группы объявлений] = cv.[Идентификатор группы объявлений]
and c.[Идентификатор условия показа] = cv.[Идентификатор условия показа] Что если значение одного из столбцов NULL? Совпадения не случится (гуглим NULL = NULL).
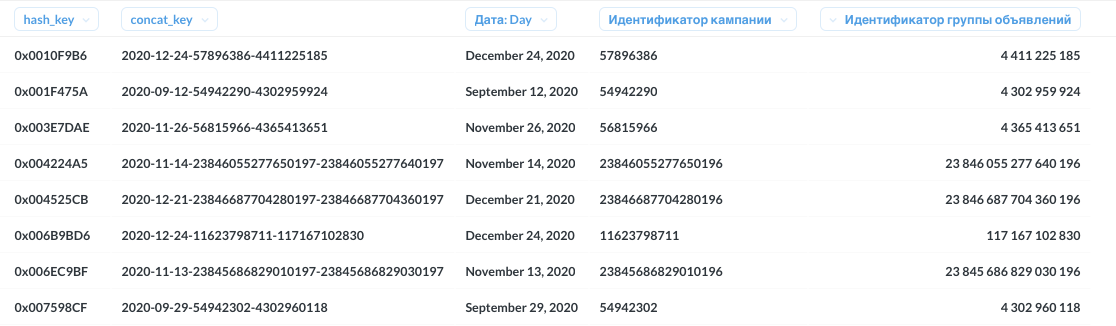
Я поступил несколько иначе: прежде чем делать джоин, я готовлю конкатенированный ключ и хеш-ключ:
-- фиксируем список полей для составного ключа
{%- set key_field_list = [
'[Дата]',
'[Идентификатор кампании]',
'[Идентификатор группы объявлений]',
'[Идентификатор условия показа]'
]
-%}
-- собираем хеш-ключ и ключ конкатенации в макросах
select
{{ concat_key(key_field_list) }} as concat_key
, {{ surrogate_key(key_field_list) }} as hash_key
...
-- условие джоина приобретает вид:
from costs c
full join conversions cv on c.hash_key = cv.hash_keyПростое и элегантное решение. И при этом ключ конкатенации может быть однозначно интерпретирован человеком.
Суррогатный хеш-ключ идеален для джоина; ключ конкатенации понятен человеку
4. Механика формирования Сквозной Аналитики
Должно быть уже заметили, что я использую full join. Да, это как раз тот самый кейс, когда мне важно не потерять ни одну из частей уравнения в случае, если совпадения не произошло: ни лид из CRM, ни строку трат из РК, ни конверсию из Я.Метрики.
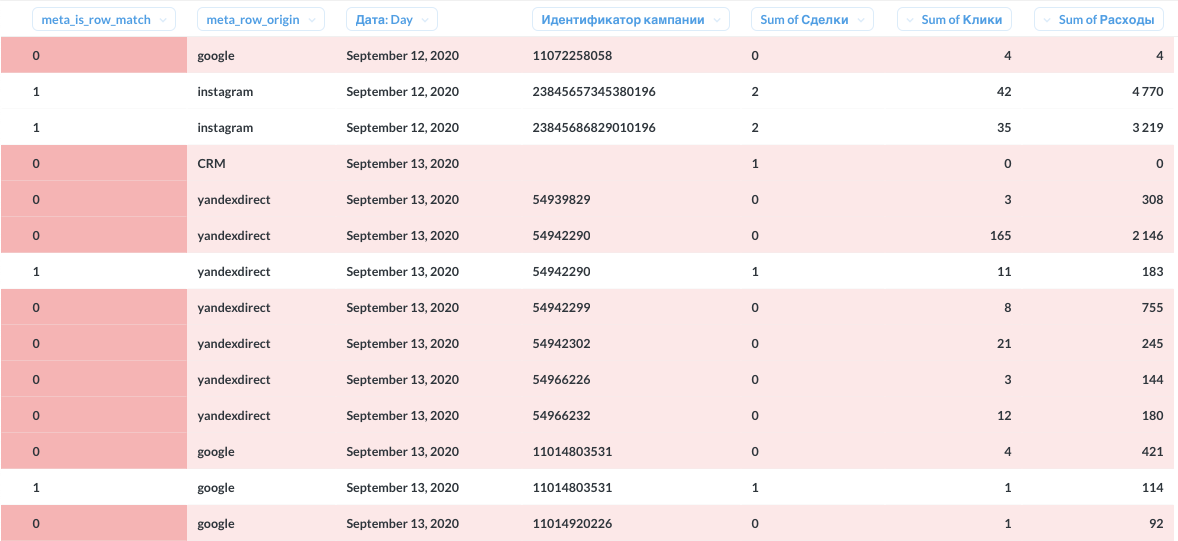
Во-первых, необходимо следить за тем, чтобы показатели не задваивались при склейке (очень запросто получается в таблицах с несколькими строками по одному ключу). Для этого я написал дата-тест, сверяющий суммы и количества с целью учета их один и только один раз.
Во-вторых, всем становится как-то досадно, когда для лида не находится источник трафика и сумма трат из РК. Для быстрого поиска причин я ввёл две мета-колонки:
Мета-колонки is_match, row_origin помогают в поиске источников проблем
В третьих, что если у владельца CRM всё схвачено и есть хитрый мастер-план по подсчету метрик? Нужно только считать как задумано. Нет проблем, сделать можно всё, что угодно. Даже так:
select
...
, sum(1) as [Сделки]
, sum(CASE WHEN [Теги] LIKE '%первич%' THEN 1 ELSE 0 END) as [Сделки - первичная коммуникация]
, sum(CASE WHEN [Статус сделки] LIKE '%успешн%' THEN 1 ELSE 0 END) as [Сделки - успешно реализовано]
, sum(CASE WHEN [Статус сделки] LIKE '%успешн%' THEN [Сумма] ELSE 0 END) as [Сумма - успешно реализовано]
...5. Модель атрибуции может стать причиной расхождений в показателях
Несоответствие данных это моя самая большая боль. Непрекращающиеся итерации сверки данных и поиска причин расхождений. С одной из них я довольно долго промучился, пока не нашел способ явно задавать модель атрибуции для выгрузки по API из Яндекс.Метрики. В теле запрашиваемого измерения необходимо явно указать модель атрибуции, например ym:s:<AttributionModel>UTMSource:
ym:s:lastsignUTMSource -- последний значимый источник
ym:s:firstUTMSource -- первый источник
ym:s:lastUTMSource -- последний источник
ym:s:last_yandex_direct_clickUTMSource -- последний переход из Директа
6. Витрины необходимо регулярно актуализировать (обновлять)
Оказывается это не так-то просто. Я могу дергать запуски скриптов вручную, но в продуктивном решении хочется расчеты выполнять по заданному расписанию и делать это надежно.
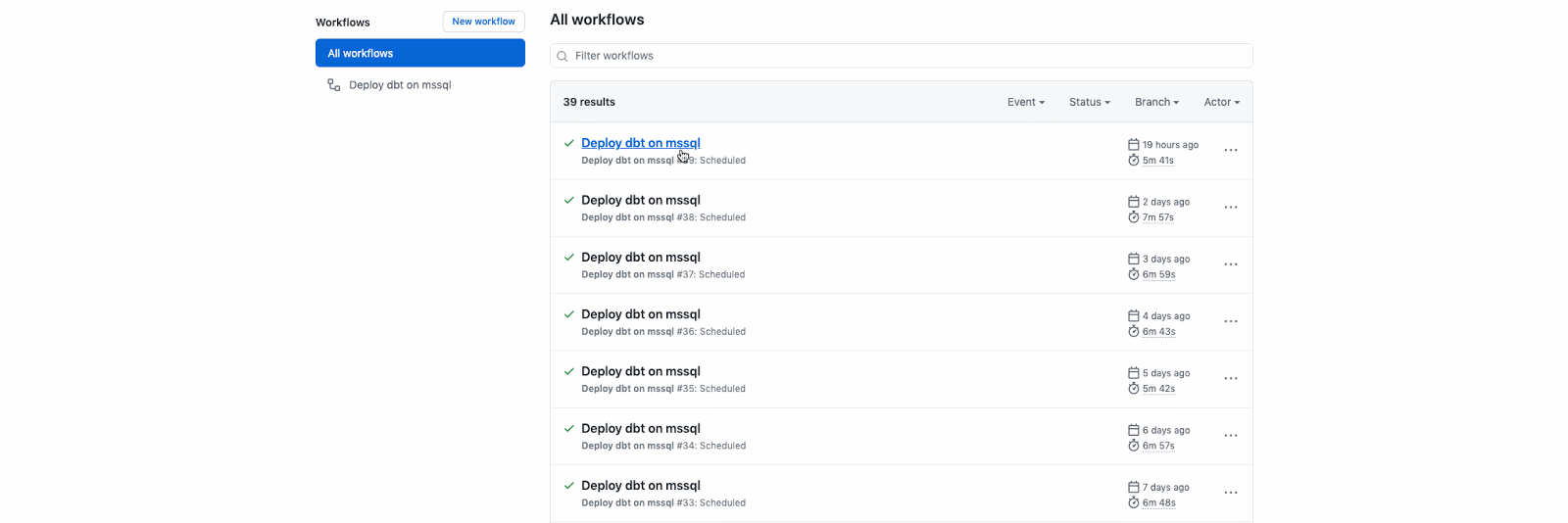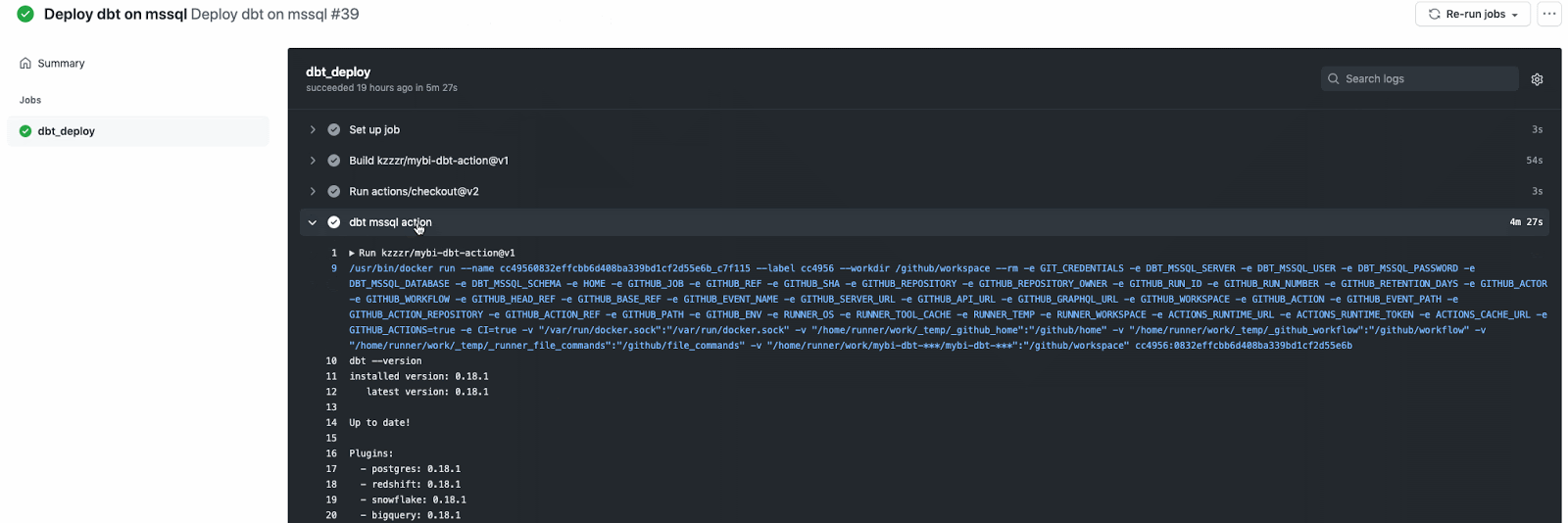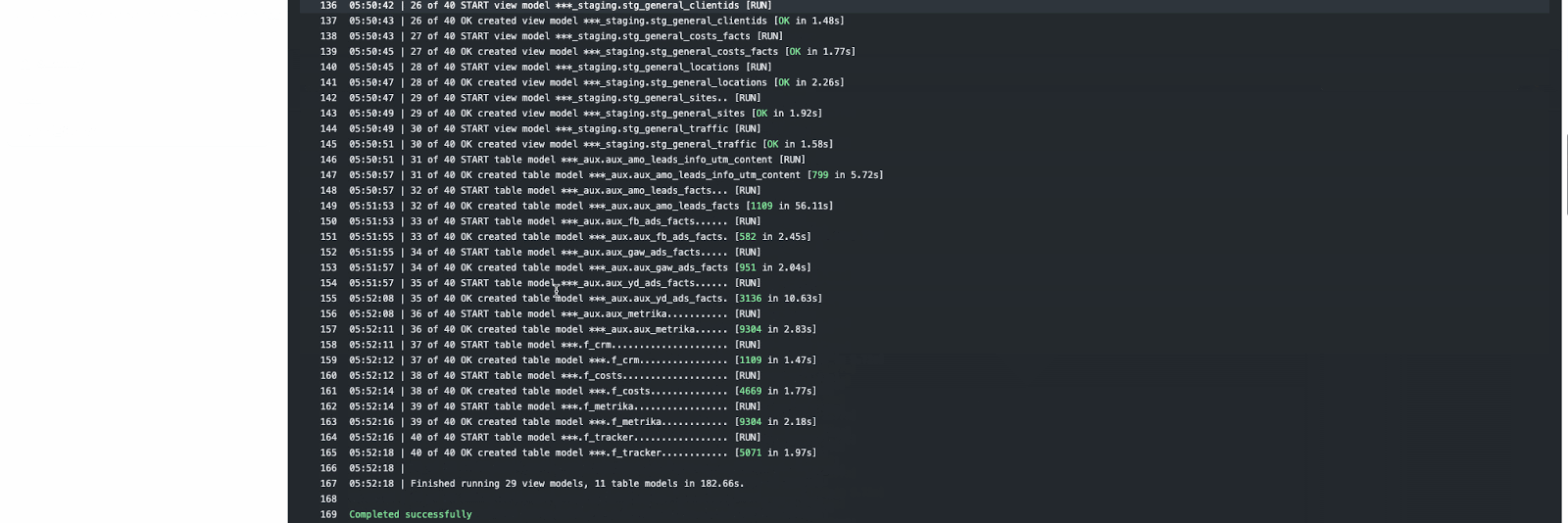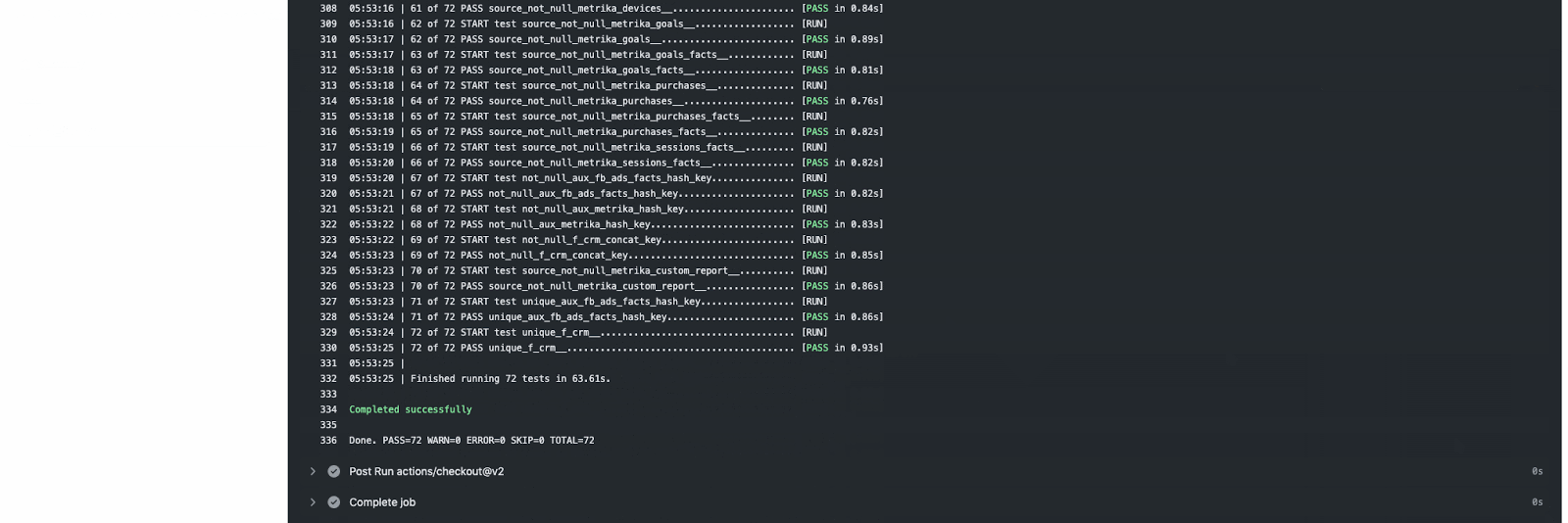
Автоматизация формирования витрин данных с помощью Github Action
И тогда я создал Github Action kzzzr / mybi-dbt-action — действие, которое автоматически разворачивает Docker-контейнер, устанавливает зависимости, подключается к СУБД, выполняет расчеты витрин, прогоняет тесты. Потратил значительное количество времени, зато теперь витрины собираются в автономном режиме, пока я спокойно сплю.
Абсолютный контроль над данными и результатами. Прозрачность и управляемость. Все алгоритмы, функции, парсинг и соединения как на ладони. Самодокументируемый код.
Да, порог входа для новичка довольно высок. Зато любые изменения — максимально быстро. Я могу слепить из данных всё, что угодно. Я не скован рамками и ограничениями других решений. И мне это нравится.
— Добавь новый аккаунт? Поменяй коэффициент?
— 1 минута на точечное редактирование кода и 5 минут на расчет витрин.
— Что, так быстро?
— Именно.
Считайте, что к этим пунктам я уже поставил галочку в своём TODO:
Конечно, он у меня есть. Следующими шагами я хотел бы сделать:
Мне нравится мой pet-project, хотя я всё еще не дал ему легендарное название. Этой публикацией я преследую несколько целей:
Я буду публиковать новости, связанные с этим проектом в telegram-канале https://t.me/enthusiastech.
Следите за обновлениями и задавайте вопросы, я буду рад на них ответить.
Благодарю за внимание.
VK объявляет о приобретении 40% компании Intickets.ru (Интикетс). Это облачный сервис для контроля и управления продажей билетов на мероприятия. Сумма…
OpenAI готовится запустить собственную поисковую систему на базе ChatGPT. Информацию об этом публикуют западные издания. Ожидается, что новый поисковик может…
Центр управления связью общего пользования (ЦМУ ССОП) Роскомнадзора рекомендовал компаниям из реестра провайдеров ограничить доступ поисковых ботов к информации на российских сайтах.…
Apple возобновила переговоры с OpenAI о возможности внедрения ИИ-технологий в iOS 18, на основе данной операционной системы будут работать новые…
Конкурсный управляющий российской «дочки» Google подготовил 23 иска к участникам рекламного рынка. Общая сумма исков составляет 16 млрд рублей –…
Google завершил обновление основного алгоритма March 2024 Core Update. Раскатка обновлений была завершена 19 апреля, но сообщил об этом поисковик…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}